
As part of the recently announced Aerospike Database 5, multi-site clusters are now a supported configuration. Aerospike database has supported a cluster architecture for almost a decade. This post describes what is different in multi-site clusters. Specifically it describes in greater detail how multi-site clusters provide strong resiliency against a variety of failures
Accelerating Global Business Transactions
The changes in the user behavior and expectations brought about by mobile devices and digital transformation are accelerating the trend of global business transactions. Today, users are connected 24×7, across the globe, and expect immediate results whether they are making payments to their friends, ordering a product on a site, or tracking a package. To respond to these changes, businesses must be always-on and respond quickly to their customers and partners that can be anywhere. The database is a key enabler of the technology platform driving these capabilities, and must have the following characteristics:
multi-site: has global footprint to reflect business presence
always on: is able to automatically recover from a variety of failures
strongly consistent: provides guarantees against staleness and loss of data
cost effective: inexpensive to buy and efficient to operate
As we will see below, a multi-site cluster is a good fit for these needs of global business transactions.
What are Multi-Site Clusters?
A multi-site cluster is essentially a regular cluster: it has multiple nodes, and the data is sharded in many partitions, each with a number (replication factor) of replicas, and the replicas are evenly distributed across the nodes. But there are several important differences.
Geographically Separated
As the name suggests, a multi-site cluster is a cluster that spans multiple sites. Sites can be located anywhere geographically, across the same city or on multiple continents, and involve hybrid and heterogeneous environments consisting of VMs, containers, and bare-metal machines in on-premise data centers, as well as private and public clouds.
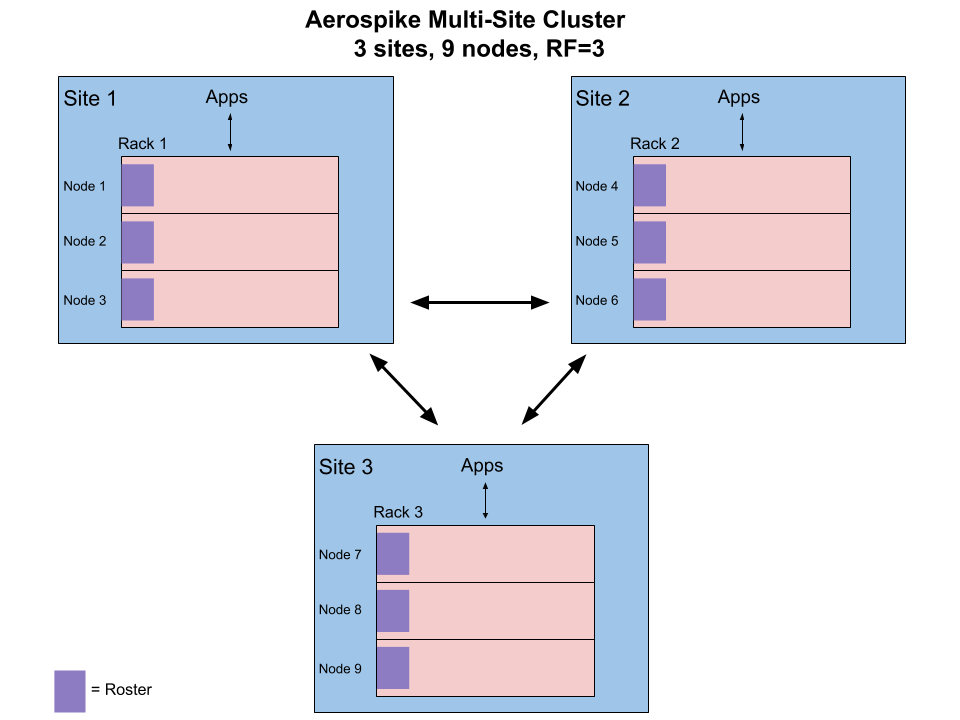
A 3-site cluster
Typically, nodes in a multi-site cluster are identically sized and evenly distributed across all sites to enable symmetry in performance and recovery.
Strongly Consistent
The key use case for a multi-site cluster is business transactions, and as such consistency of data across all sites is critical. Therefore, a multi-site cluster is configured in the Strong Consistency (SC) mode. In the SC mode, all replicas are synchronously updated, thus maintaining one version of the data so that the replicas are immediately and always consistent. Eventually consistent systems allow multiple versions that must be merged, requiring applications to be willing to work with stale versions and lost writes.
The other, Available during Partitions (AP), mode in Aerospike does not provide guarantees against lost or stale data in the event of a cluster split, for instance, and is unsuitable for business transactions that cannot tolerate inconsistent data.
Rack Aware
An Aerospike cluster can have nodes across multiple physical racks, and rack-aware data distribution ensures balanced distribution of data across all racks. In the context of a multi-site cluster, a rack is equivalent to a site, and rack-aware data distribution ensures no duplicate data at any site when the replication factor (RF, the number of replicas for all data partitions) is less than or equal to the number of racks (N). It ensures at most one replica when RF < N, and exactly one replica when RF = N.
Typically, a multi-site cluster is configured with RF=N because it provides the best performance and resiliency characteristics. With RF=N, each site has a full copy of the entire data, and therefore all reads can be very fast as they are performed on the local replica. Also, in case of a site failure, the remaining site(s) has all data to serve all requests.
While a multi-site cluster with 2 or 3 sites with the replication factor of 2 or 3 respectively are common, different configurations with more sites and replication factors are also supported.
“Always On” Resiliency
Aerospike clusters support zero downtime upgrades with full data availability. Also in multi-site clusters, all planned events including upgrades, patches, and hardware maintenance can be performed with no interruption to service.
Multi-site clusters also support automatic recovery from most node, site, and link failures. Automatic recovery and continuity in the event of a site failure is a key reason for businesses to choose multi-site clusters.
How Aerospike recovers from various failures is explained further below.
Fast Failure Detection and Recovery
All nodes maintain the healthy (or original) state of the cluster called “the roster” which includes the nodes and replica-to-node map for all data partitions. All nodes exchange heartbeat messages with every other node in the cluster at a regular (configurable, typically sub-second) interval. The heartbeat messages include all nodes that a node can communicate with. Using a specific number (configurable) of recent heartbeats, a primary node is able to determine quickly any failures in the cluster and the new membership of the cluster (i.e., the nodes that can all see one another), and it disseminates the new cluster definition to all connected nodes. With this information, each node can make independent decisions about any of its roster replicas that must be promoted to become new masters to replace failed masters, as well as any new replicas that it must create to replace failed replicas. This process of failure detection and recovery to form a new cluster takes just a few seconds.
Availability During Migration
New replicas are populated by migrating data from the master. While migrations typically take longer than a few seconds, especially when they involve inter-site data transfer, the partition would remain available for all operations while the migration is in progress.
Recovery from Failures
Next we will look into the details of recovery from various failures. It is important to note the two invariants of the SC cluster and partition availability rules during a cluster split that ensure strong consistency.
SC Cluster Invariants
The following two invariants are preserved in an operational SC cluster at all times. Recovery from a failure ensures these invariants are met before new requests are serviced.
A partition has exactly one master. At no time can there be more than one master in order to preserve a single version of data. Potential race conditions involving an old and a new master are resolved using the higher “regime” number of the newer master. The master is the first available roster replica in the partition’s succession list of nodes. A partition’s succession list is deterministic and is derived solely from the partition id and node ids.
A partition has exactly RF replicas. These are the first RF cluster nodes in the partition’s succession list of nodes.
Note the second invariant does not mean that all replicas must have all data for continued operation; partitions remain available while background migrations bring replicas to an up-to-date state.
Partition Availability Rules
A partition may be active only in one sub-cluster during a cluster split to preserve strong consistency. The following rules dictate whether a data partition can be active in a sub-cluster:
A sub-cluster has the majority of nodes and at least one replica for the partition.
A sub-cluster has exactly half nodes and has the master replica for the partition.
A sub-cluster has all replicas for the partition.
Node Failures
In the following diagram, the cluster consists of 9 nodes across 3 sites with a replication factor of 3. When a node fails, such as Node 1 as shown in the diagram, all partition replicas on the node become unavailable.
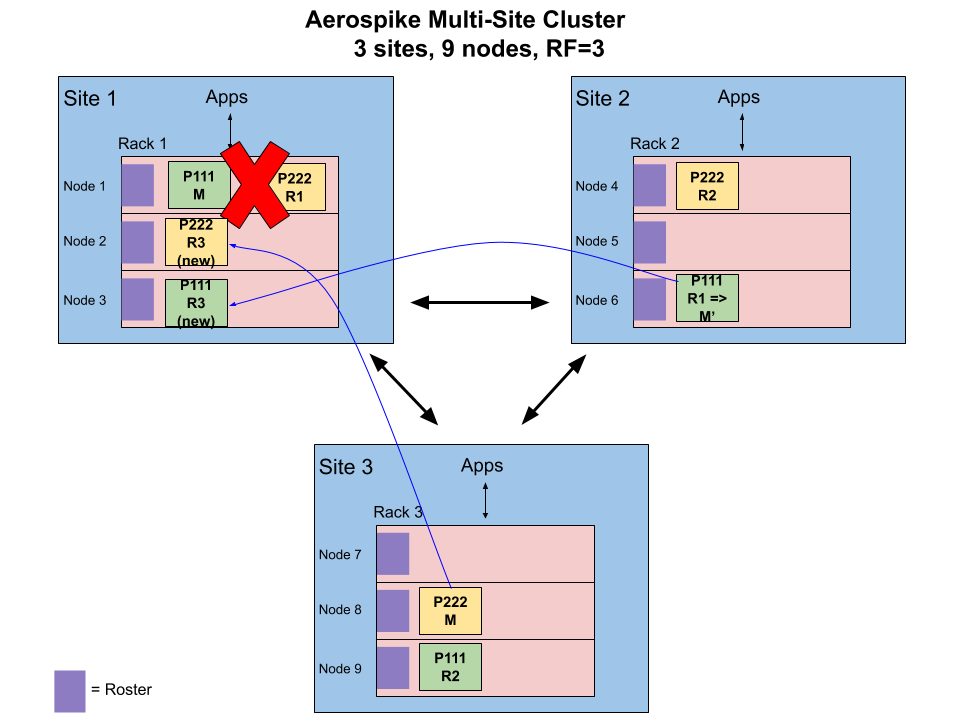
Node Failure: Master roles are transferred and new replicas are created
The cluster detects the node failure and acts to reinstate the two invariants mentioned above.
For every master replica on Node 1, the next roster replica in the partition’s succession list becomes the new master. As illustrated in the diagram, P111-R1 on Node 6 becomes the new master.
For every replica on Node 1, a new replica is created to preserve the replication factor. Also, per rack-aware distribution rules, the new replica must reside on the Site 1 to preserve one replica per site. As illustrated in the diagram, new replicas P111-R3 on Node 3 and P222-R3 on Node 2 are created.
With this, the cluster is ready to process new requests while the new replicas continue to be populated from their respective master.
Site and Link Failures
The following diagram shows a site failure (Site 1) and link failures (Site1-Site2 and Site1-Site3). Both result in the same recovery and end state, and so let’s consider the latter for our discussion.
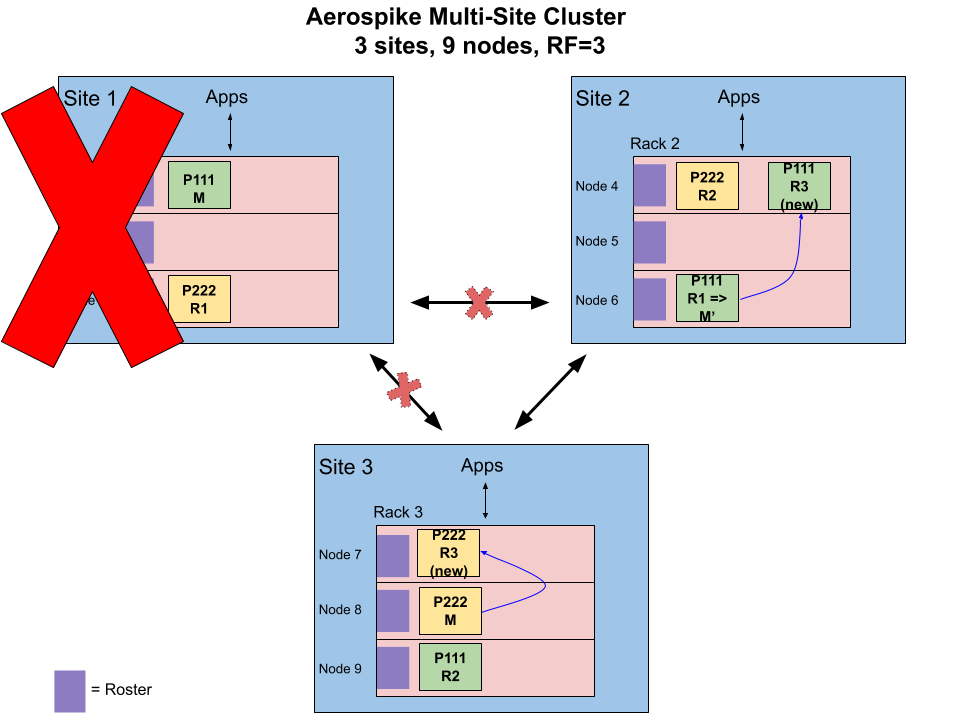
Site or Link Failures: Sites 2 and 3 form the new cluster
When the links fail, the cluster is split into two sub-clusters: one with nodes 1–3 and the other with nodes 4–9. Each sub-cluster acts to first determine which partitions are active by applying the three rules mentioned above:
The sub-cluster with nodes 4–9 has the majority of the nodes and therefore is the majority sub-cluster. Since it has at least one (actually exactly two, one each on Site 2 and Site 3) replica for every partition, it can serve all requests for all data. No data is available within the other (minority) sub-cluster.
No sub-cluster has exactly half the nodes, and therefore this rule is not applicable. (This rule would apply for a 2-site cluster with even nodes.)
No sub-cluster has all replicas for any partition, and therefore this rule is also not applicable. (With Rack Aware distribution, this rule is never applicable in multi-site clusters.)
The majority sub-cluster then proceeds to reinstate the two invariants and promotes appropriate roster replicas to replace master replicas in the other sub-cluster and also creates new replicas for all replicas in the other sub-cluster.
With this, the cluster is ready to process new requests while the new replicas continue to be populated from their respective master.
Return to Healthy State
When failures are fixed, the cluster returns to a healthy state through a similar process of detection and recovery described earlier. The roster (i.e., original) masters regain the master role, roster replicas are brought up-to-date, and any new replicas are dropped. Requests received by a replica while it is receiving updates are proxied to appropriate replica.
Comparing Resiliency in 2-Site and 3-Site Clusters
The following table demonstrates how a 3-site (RF=3) cluster provides superior resiliency as compared to a 2-site (RF=2) cluster.
Essentially, a 3-site cluster automatically recovers with full availability of data from any single site failure and node failures spanning any two sites that a 2-site cluster cannot. It can also recover from a two site failure with manual intervention that requires “re-rostering” of the cluster with the surviving nodes.
A 3-site cluster is more resilient than a 2-site cluster
The scenarios are described in more detail below.
2-Site Cluster (RF=2)
Node failures: The cluster can automatically recover from up to a minority node failures on the same site. For node failures across sites, the cluster will be partially available as some partitions would lose both replicas and thus would become unavailable. For a majority node failures, the cluster will neither recover automatically nor will be fully available.
Site failure: The cluster can automatically recover from a minority site (ie, the site with fewer nodes) failure in the case of an odd nodes cluster. When the site with equal nodes (in an even nodes cluster) or majority nodes fails, a manual intervention to re-roster the remaining nodes is needed to make the cluster fully operational.
Link failure: In an odd nodes cluster, the majority site will remain operational, and so will the applications that can connect to the majority site. In an even nodes cluster, both sites will remain operational for exactly half the partitions for which they have the master replica. For an application to work, it must be able to connect to all nodes on the two sites.
3-Site Cluster (RF=3)
Node failures: Just like the 2-site cluster case, a 3-site cluster can automatically recover from up to a minority node failures across any two nodes. For node failures involving all three sites, the cluster will be partially available as some partitions would lose all 3 replicas and would become unavailable. For a majority node failures, the cluster will neither recover automatically nor will be fully available.
Site failures: The cluster can automatically recover from a single site failure. When two sites fail, a manual intervention to re-roster the nodes on the third site is needed to make the cluster fully operational.
Link failures: In one or two link failures that allow two sites to form a majority sub-cluster, an automatic recovery is possible. If all three inter-site links fail, the operator can decide to re-roster the nodes at any one of the three sites to create an operational cluster. For an application to work, it must be able to connect to all nodes of the operational cluster.
Other Considerations
Write Latency Write transactions update all replicas synchronously. Therefore write latency is dictated by the maximum separation between any two sites. This can range from a few milliseconds in a cluster spanning multiple zones in the same region to hundreds of milliseconds for a cluster across multiple continents. Application requirements for strong consistency, disaster recovery, and write latency should be balanced to come up with the optimal cluster design.
Node Sizing Node sizing should take into account maximum node failures on a site, as the content and load from the failed nodes will be distributed to the remaining nodes on the same site in Rack Aware distribution. In the extreme case, it is possible to have a single node hold all the site’s replicas and server all its requests, however the cluster may not function optimally.
Migration Time With high bandwidth connectivity, a replica can be migrated quickly. Migrations are typically throttled so that the cluster can provide adequate response to the normal workload. Applications are unlikely to experience higher latency during this period if the workload is not bandwidth intensive. Multiple simultaneous node failures may extend the migration duration and latency depending on the configuration and network bandwidth.
Global Data Infrastructure For a different class of applications that requires fast write performance, selective replication across sites to meet regulatory requirements, autonomy of site operations, but that can live with less stringent consistency guarantees, Aerospike provides Cross Data-center Replication (XDR). XDR can be combined with multi-site clusters to architect an optimal global data infrastructure to satisfy multiple applications.
Conclusion
Aerospike multi-site clusters span geographically distant sites and provide strong consistency and always-on availability at a low cost, making them a good fit for global business transactions. Multi-site clusters can quickly detect and recover from node, site, and link failures to provide “always-on” availability. Today, many deployments are successfully running mission critical transactions at scale with multi-site clusters. Multi-site clusters and Cross Data-center Replication(XDR) together provide the capabilities and flexibility in creating the optimal global data infrastructure within an enterprise.
Keep reading

Jun 17, 2026
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS

May 28, 2026
Determining the best machine learning and AI databases

May 18, 2026
The three price tags: How Redis unpredictability costs you infrastructure, engineering time, and UX

May 12, 2026
Monitoring Aerospike Enterprise in Datadog: What you get and how it works