
Or how to run SQL queries on a NoSQL database
Note: Aerospike Presto Connector is in Beta. Please reach out to us to participate in the beta program.
Aerospike is a high throughput/low latency distributed NoSQL database. Records may be retrieved based on a primary key, secondary index query, or full scan using the most basic API functionality. It’s possible to use filters to perform a selective scan on the server side and reduce network traffic.
These days the industry has a lot of use cases for running SQL queries on top of NoSQL big data clusters for ad-hoc analytics, BI, etc’. At Aerospike we looked for open-source and durable software to give us an ability to speak the language of relational databases.
Presto
Presto is an open-source, high performance, distributed SQL query engine for big data. Its modular architecture allows users to query a variety of data sources. Also, Presto uses ANSI SQL syntax/semantics to build its queries. The advantage of this is that analysts with experience with relational databases will find it very easy and straightforward to write Presto queries.
Presto architecture is simple and extensible. You can read more about the Presto concepts to get a description for each component in detail.
A few words about the presto workflow. The Presto client submits SQL statements to a master daemon coordinator. The scheduler connects through an execution pipeline. The scheduler assigns work to nodes which is closest to the data and monitors progress. The coordinator assigns tasks to multiple worker nodes and finally the worker node delivers the result back to the client.
The following diagram illustrates the architecture of Presto using the Aerospike connector.
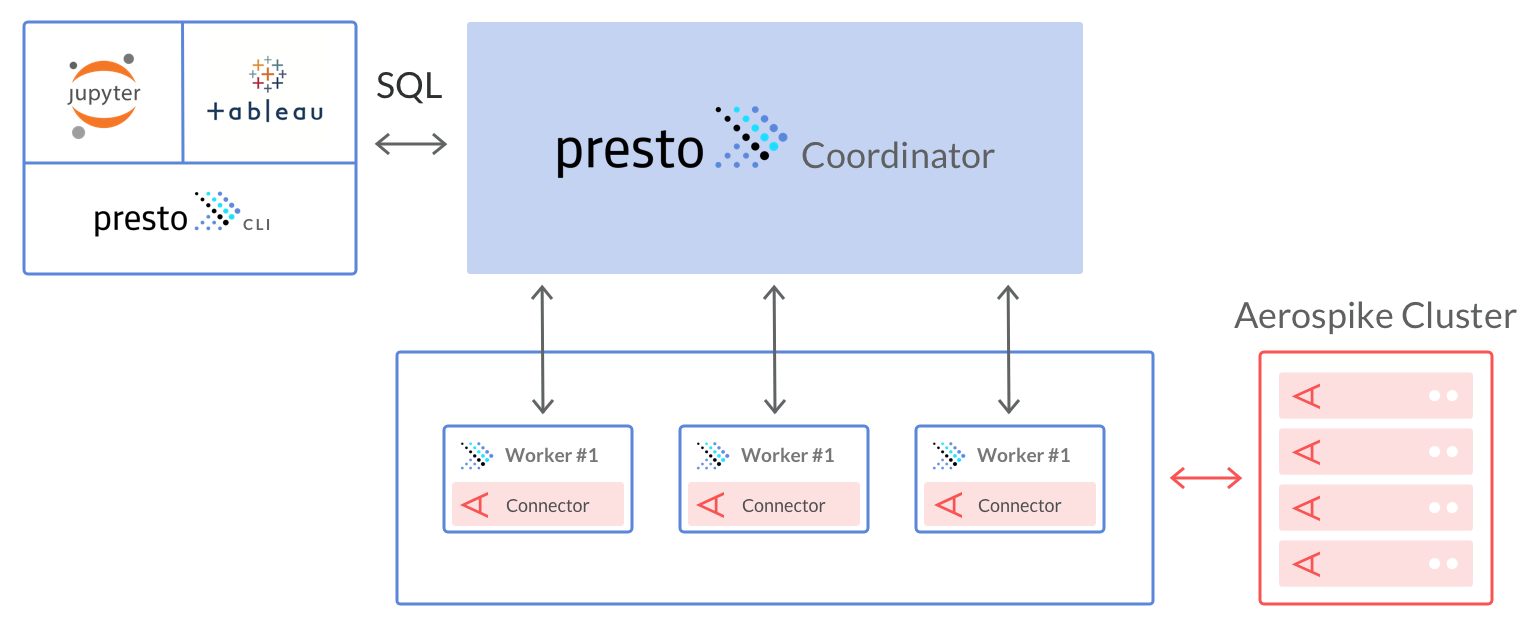
In order to understand the way Presto and Aerospike communicate, we’ll need to get through some translation tables.
Data Sources:
Aerospike | Presto |
cluster | catalog |
namespace | schema |
set | table |
record | row |
bin | column |
Variable types:
Aerospike | Presto |
byte[] | VARBINARY |
String | VARCHAR |
Integer | INTEGER |
Long | BIGINT |
Double | DOUBLE |
Float | DOUBLE |
Boolean | BOOLEAN |
Byte | TINYINT |
Value.ListValue | |
Value.MapValue | |
Value.GeoJSONValue | |
Value.HLLValue | HYPER_LOG_LOG |
More types to be supported in future releases.
Aerospike maps and lists are being translated to Presto’s JSON type, since it fits better as a generic heterogeneous data type. You can read more about Presto’s JSON functions.
Data types that are not listed in this table will be handled as a simple String type.
Installing and Configuring the Connector
Now, when we understand how the communication works, it’s the time to plug in our connector and start querying Aerospike data.
Prerequisites:
You’ll need an Aerospike server version >= 4.9 to ensure connector’s proper functionality.
Presto server version >= 340.
The Aerospike Presto connector is a Java application, which is distributed as a bundle of jars. In order to add the Aerospike plugin to a Presto installation, create a directory “aerospike” in the Presto plugin directory and add all the necessary jars for the plugin there.
By default, the plugin directory is relative to the directory in which Presto is installed, but it is configurable using the configuration variable catalog.config-dir. In order for Presto to pick up the new plugin, you must restart Presto.
The plugin must be installed on all nodes in the Presto cluster (coordinator and workers).
You can read more about Presto configuration.
I will not include here the full list of the connector’s configuration properties, since we add new ones all the time, as well as some of the properties’ names might change over the time until the stable release. But it is worth it to list here some of them.
Number of Presto Splits. We support Integer.MAX_VALUE splits (i.e. 2^31-1 Presto splits mapped to 4096 Aerospike partitions, splitting a partition scan with modulo operations over the digest) for parallel partition scans by Presto workers. Splits is the unit of parallelism in Presto. Hence, we can support up to ~2B Presto worker threads, setting this value too high may cause a drop in performance due to context switching.
Schema structure definition. Both schema inference and the ability to define table definitions are supported. The default behavior is schema inference. In this case, the plugin will scan the first 1K records with the further build and cache the schema based on this data. Table schema can be set using a JSON file:
{
"schemaName": "schema1",
"tableName": "table1",
"columns":[
{
"name": "id",
"type": "varchar",
"hidden": false
},
{
"name": "int",
"type": "bigint",
"hidden": false
},
{
"name": "list",
"type": "json",
"hidden": false
},
{
"name": "map",
"type": "json",
"hidden": false
}
]
}Strict/loose schema. Using this configuration we can skip or error out on the records that do not match the schema structure.
Optimizing Queries
One of the interesting things about Presto is that it supports federated queries. Meaning, we can join tables from different data sources. Configuration of multiple Aerospike clusters within a single Presto environment is possible by creating multiple catalogs.
Another thing that might be interesting is the performance. Will it be fast enough, as we are used to working just with Aerospike? We think it is, and Presto has plenty of optimization strategies that make it swift.
We leverage Presto predicate pushdowns utilizing filters to improve performance by returning a limited number of records from the Aerospike server and to reduce network traffic and further Presto computation.
The connector supports adding a record key to the table as a column. This way queries with the primary key in a filter will take advantage of using batch reads instead of a full scan.
The Aerospike Presto connector supports statistics collection for Presto’s CBO (cost-based optimizer). Currently only the row count statistic is supported. These statistics are useful for various query optimizations. If we collect table statistics the CBO can automatically pick the join order with the lowest computed costs. Another interesting join optimization is dynamic filtering. It relies on the stats estimates of the CBO to correctly convert the join distribution type to “broadcast” join. EXPLAIN is an invaluable tool for showing the logical or distributed execution plan of a statement and to validate the SQL statements. Aerospike statistics can be turned on using a connector’s configuration parameter.
When Presto is scheduling a query, the coordinator queries a connector for a list of all splits that are available for a table. The coordinator keeps track of which machines are running which tasks, and what splits are being processed by which tasks. We can control the number of parallel splits for the Aerospike connector using aerospike.split-number configuration parameter.
These are the main optimization settings you might want to look at but there are many more out there.
Presto Clients
Before I wrap up, let’s name some of the well known clients to be used with Presto.
The Presto CLI provides a terminal-based, interactive shell for running queries. The CLI is a
self-executing JAR file, which means it acts like a normal UNIX executable.
Tableau is a popular data visualization tool for BI. It has built-in support for Presto.
Jupyter Notebooks is one of the most popular notebooks for sharing code,especially among Python users. It allows you to execute SQL queries against Presto clusters.
Presto is an open-source project that is widely adopted in the industry, and this integration adds another highly useful way for Aerospike users to query and join data in an Aerospike database cluster.
I hope this brief introduction has given you essential information to get started with the Aerospike Presto connector. If you’re аn Apache Spark user, you might also be interested in the Aerospike Spark connector.
Watch our documentation for more information and examples, or subscribe to The Aerospike Standup to hear about Aerospike news such as the Presto connector.
Star the repos you like and use in github.com/aerospike and github.com/aerospike-community, and get involved. Also, you can follow me on GitHub to get updated with the newest Aerospike ecosystem development.
Keep reading

Jun 17, 2026
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS

May 28, 2026
Determining the best machine learning and AI databases

May 18, 2026
The three price tags: How Redis unpredictability costs you infrastructure, engineering time, and UX

May 12, 2026
Monitoring Aerospike Enterprise in Datadog: What you get and how it works