
With the growing interconnectedness of the world, the need for global applications is on the rise. Users are constantly on the move and they may try to access applications from anywhere in the country or in the world. The users should get the best experience wherever they are. Availability and proximity of data to the users are a key requirement for better user experience. At the same time, proximity needs to honor the data locality regulations, such as Europe’s General Data Protection Regulation (GDPR).
Sometimes, distributed applications depend on replicated data that needs to be synchronized across multiple locations to make globalized decisions. For example, a company may want to run an ad campaign across the USA with a budget limit across the country. It will be inefficient to consult a centralized database for every ad spend for each zone when there can be millions of ads shown every second. Instead, each zone can let other zones know how much money it is spending on a near real-time basis. If every zone has all the information, each zone can check its spend against the global limit (with an acceptable buffer, based on business model, to allow for information delay).
Business Continuity Plan (BCP) and Disaster Recovery (DR) are pretty common requirements with the 24/7 activity. Though these terms are used interchangeably, they mean slightly different things. If all the necessary data is replicated across datacenters, BCP can be achieved by switching the operations from the affected datacenter to the good one. The users will be able to continue their usual activity albeit with a degraded performance for some of the users. DR deals with restoring the operations on the site that was affected. The affected datacenter needs to catch up with the data that it missed.
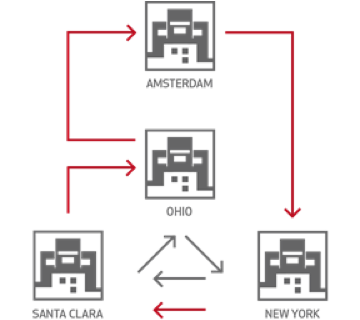
Use cases like the above need a global distributed data architecture. Aerospike 5.0 offers two solutions to meet these needs.
Multi-site Cluster: A single cluster spanning multiple datacenters and replicating data synchronously. The response of write transaction is sent to the client after the replication is done from master to the replica
Cross-datacenter replication (XDR): In version 5.0, XDR has been completely redesigned for better functionality and flexibility. Multiple individual clusters connected via XDR replicate data asynchronously after a write transaction completes at the originating cluster. XDR can also ship to non-Aerospike destinations like Kafka/JMS/Apache Pulsar queues.
In this blog, we will briefly touch upon the differences between the two. But the main focus of the blog is how the redesigned XDR enables many patterns used in global datacenter architecture. If XDR is new to you, see XDR architecture to become familiar with different XDR deployment scenarios like active-passive, active-active, mesh, hub-and-spoke.
In this article we use the term ‘datacenter’ (also called a “DC”) in a broad sense to mean co-located compute and storage. Physically, two datacenters, located in public or private clouds, might be spread across vast geographical distances, they can be in two seperate buildings, or they can be in two separate racks.
Multi-site Cluster vs XDR
There are different tradeoffs between multi-clustering vs XDR. One should choose based on the use case and the guarantees expected from the system. The key differences are described in the table below.
Multi-Site Clustering | XDR |
Consistency: As the replication between master and replica nodes is synchronous, it gives better consistency. The namespace in a multi-site cluster can be configured for strong-consistency. | Consistency: As the replication between source and destination clusters is asynchronous, clients at the destination cluster may see older data after the write is completed at the source cluster. Strong-consistency is not possible across source and destination clusters. (Source and destination cluster can individually be strongly-consistent). |
Latency: Latency of the writes can be high due to synchronous replication across datacenters. Latency of reads will be low if the datacenter has a full copy of the data. | Latency: Latency of the write will be low as the replication between master and replica is local. The response to the write transaction will not wait for XDR to replicate the write. Latency of the read will also be low as the data is local. |
Write-Write conflict will not arise in this configuration as there is only one master as it is a single cluster. All the writes will go to that node only. | Write-Write conflict might happen in an active-active topology as writes might happen simultaneously on two or more clusters for the same key. There are few techniques to handle such conflicts with the knowledge of the application. |
It is a single cluster and therefore governed by the same configuration for each namespace; for example, configs like strong-consistency, replication-factor, storage-engine. | Each cluster can have its own configuration. For example, the replication-factor in source cluster can be 2 and in the destination cluster can be 3 |
New functionality in XDR 5.0
The new capabilities enhance ease, control, and flexibility in managing data from multiple sources and sent to multiple destinations.
Decoupling of DCs
In old XDR, a well-known problem is that a slow DC (datacenter) can slow down shipping to all the other DCs. The slowness can be either due to network issues or because of writes taking more time at the DC. The reasons are many and historical.
In XDR 5.0, we now have a dedicated thread for each destination DC. All the internal data structures, configuration, statistics are maintained per DC. There is no dependency between DCs. So, even if a link is down or flaky for a DC, all the other DCs can continue totally unaffected.
Low-latency design
We continued Aerospike’s DNA of high performance with the redesign. We exploited several techniques like cache-friendliness, high-granular locking, thread-affinity.
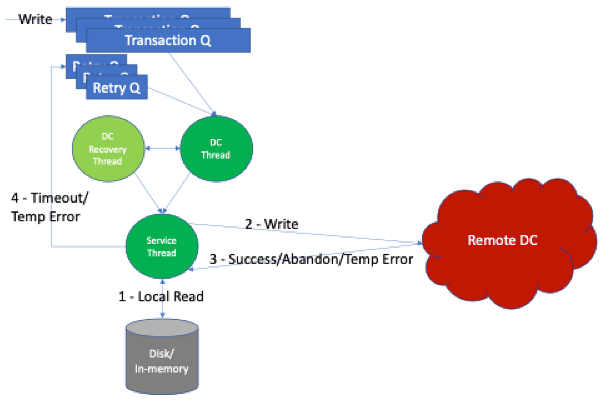
The above picture gives the gist of the design. It represents the components involved in the life cycle of record in XDR for a destination DC. When a write happens in the source DC, metadata will be submitted to an in-memory transaction queue meant for each of the destination DCs.
As mentioned before, there is a thread for each destination DC. The DC thread is the orchestrator of the overall processing. It is also responsible for throttling if necessary. It will pick the metadata of a write from the in-memory queue, and schedule the work for the service thread.
Once a ship request is assigned to the service thread, the same service thread will take care of all phases of the lifecycle of shipping thereby achieving thread-affinity and cache-friendliness. The same service thread will read from disk, ship to the destination DC, and wait for the response. On a successful response, the service thread will flag the success of this shipping and release resources associated with it. If the shipping was not successful either due to a timeout or due to a temporary error in the destination DC, it will be put back in the retry-queue. Elements in the retry-queue will be picked by the DC thread and the whole process begins again. Each of these events has associated metrics for monitoring, which are explained in detail in “Lifecycle of record shipment“
Dynamic DC creation
In old XDR, one cannot dynamically create and delete DCs. However, there is a workaround by putting a skeleton DC in the configuration that does not contain any configuration. The configuration for this skeleton DC can be set dynamically using info commands.
In XDR 5.0, this unnatural artifact of a skeleton DC has been removed. A DC can be created, configured, and destroyed dynamically using the info commands. In other words, the whole life cycle of a DC can be managed with info commands.
Important note: A DC’s configuration done via info commands will not be persisted in the config file. Be sure to add the changes to the config file if you need the config to persist as the changes made via the info commands are not persisted and will be lost on a restart.
Configuration per DC per namespace
In old XDR, the XDR-related configurations at the namespace level are applied to all the DCs to which the namespace is configured to ship. This causes unnecessary entanglement of configuration across DCs. For example, if a particular set is configured to not ship, it is not shipped to any DC.
In XDR 5.0, DC & namespace configurations are inverted. In old XDR, a DC is added/enabled for a namespace. However, in XDR 5.0, a namespace is added/enabled for a DC (see the example in the section below). In XDR 5.0, all the namespace configurations will be per DC per namespace. This gives a lot of flexibility to use XDR in a variety of new ways. See some detailed examples for different topologies like active-passive, mesh, star, and chain. A few noteworthy configurations are described below
Forwarding
Now that forwarding can be enabled per DC per namespace, this will allow us to create new topologies that were not possible before. A commonly requested feature was to be able to create a set of read-write DCs that fully replicate among themselves, but allow forwarding to a few read-only DCs. It is now possible with the per DC per namespace configuration.
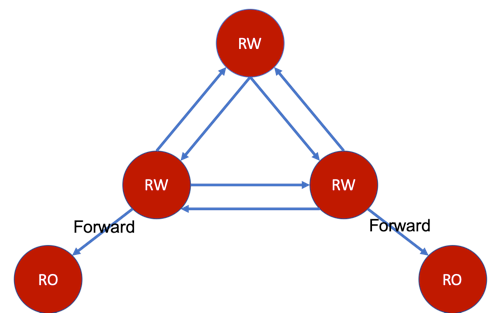
Set-level DC
Another requested feature was to be able to specify destination DC at set-level. This can be done indirectly in the new XDR with the per DC per namespace configuration. As in old XDR, we allow blacklisting and whitelisting of sets. For each DC, for a given namespace, one can whitelist only a single set thereby achieving the functionality of specifying DC at set-level. In XDR 5.0, the config looks something like the following.
xdr {
dc DC1 {
node-address-port 10.0.0.1 3000
namespace test {
ship-only-specified-sets true
enable-set set1
}
}
dc DC2 {
node-address-port 10.1.0.1 3000
namespace test {
ship-only-specified-sets true
enable-set set2
}
}
}Bin projection filter for conflict avoidance
Similar to sets, we now can configure which bins will be shipped. This can be used for conflict avoidance. A known limitation in XDR is the ability to handle write-write conflict with multiple active DCs. This is particularly a hard problem when more than 2 active DCs are present. However, in some use cases, the problem can be solved by conflict avoidance.
With only record-level shipping, we used to recommend conflict avoidance by splitting the value into multiple records in different sets, make each DC update only one of the split, and merge them during the read. While this approach is fine, one downside of it is the extra memory required for the split records. Another downside is the necessity to read multiple records to do the merge.
With the bin projection filter we can configure only a specific bin (or a specific set of bins) to be shipped by a DC. Thus, a client application in the DC has to update only the bin that was shipped. Similarly, other DCs will ship their corresponding bins to this DC. Conflict can be avoided in this way. Finally, the application can read a single record and merge the split values based on the business logic.
Rewind
There can be situations where XDR did not ship records to the destinations. Reasons can be many like configuration mistakes or shipped records are rejected/lost at the destination. In the old XDR, we used to recommend touching records that were updated recently so that XDR will ship them again. But users needed to write a custom application for this.
In XDR 5.0, we provide an option to rewind to a previous point in time. This can be done when dynamically enabling a namespace to ship to a destination DC. Users can express how much to rewind in seconds. This feature will greatly simplify what a user needs to do to overcome the problem.
Warning: We provide an option to rewind “all”. As the name suggests, it will rewind all the way back and ship all the records in the namespace (according to the configuration). This functionality should be used responsibly. Our suggestion is to use this when the data set is small. XDR is not necessarily the most efficient way to ship a bulk of data (in gigabytes) in one shot. It is designed and optimized to ship incremental updates, and it throttles accordingly. A more efficient way to ship bulk data is to take a backup at the source DC, zip it, transfer it with scp/rcp/sftp to the destination DC, and restore it at the destination DC.
Rewind does not guarantee shipping of deletes. Rewind is based on the primary index tree and if the record entry is permanently deleted from the primary index, there is no way for XDR to know that the record was deleted. If the tombstones still exist, XDR will get a chance to ship them as deletes.
Connectors
XDR is capable of shipping the changes (change notification) to external connectors which in turn will write to queuing systems like Kafka or JMS. Prior to XDR 5.0, we used to send the change notifications to external systems over HTTP. For that we used libcurl and nghttp2 libraries to support HTTP v2. We were early adopters of HTTP v2 with these libraries, but we have seen both performance and stability issues over time which affected some customers. While the stability issues may be fixed over time, we were forced to rethink the performance aspects for the long term.
Aerospike provides the connectors to forward the records to Kafka, JMS, (and Pulsar in the making). Now that Aerospike builds the end-to-end system, we do not need the flexibility provided by HTTP. We are not ready to give up performance for the sake of flexibility. So, we chose to build the receiving server ourselves. This allows us to move to lightweight and existing wire-protocol that we use for client-server communication over TCP. This greatly improves the performance while giving us full code control over components involved.
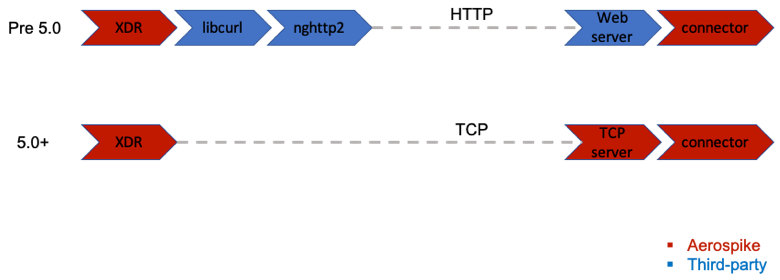
Sending user-key on deletes
In old XDR, for change notification to external connectors, there is no ability to send the user-key (record’s key stored by the user) while notifying deletes. This forces the external systems to use the digest (hash of the key) to handle the delete notifications which may not always be feasible. The main reason is that the digestlog (which in the old XDR stored changes meant for shipping) did not have a mechanism to store the user-key.
In XDR 5.0, we introduced the concept of xdr-tombstones to handle deletes, both user-initiated deletes and deletes from expiration or eviction by the Namespace Supervisor (nsup). The xdr-tombstones can hold the user-key (if one is sent by the user). This key is now sent as part of the delete notification.
Conclusion
XDR 5.0 brings great improvements in flexibility that can adapt to new use cases. Users whose datacenters are not far apart can expect better latency in shipping. We addressed some of the common pain points of existing customers. This redesign will give much smoother operational experience for existing customers even if they do not use any new functionality. From an engineering perspective, the new redesigned platform gives us the ability to add new features without being shackled by some limitations in the older design. You can expect more improvements in XDR going forward.
Learn More
Keep reading

Jun 17, 2026
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS

May 28, 2026
Determining the best machine learning and AI databases

May 18, 2026
The three price tags: How Redis unpredictability costs you infrastructure, engineering time, and UX

May 12, 2026
Monitoring Aerospike Enterprise in Datadog: What you get and how it works