Blog

Aerospike 4.5.2 which was released on April 1st, 2019, is unique in that it implements a way to relax consistency in certain situations to allow increased availability.
About a year ago, Aerospike announced the availability of Aerospike 4.0 with support for strong consistency. The strong consistency technology of Aerospike has been used in a number of production installations most notably at the launch of a major European bank’s instant payment system to transfer amounts between any two European bank accounts.
When an Aerospike namespace is configured to be in strong consistency mode, the system ensures that all successful writes are preserved with no data loss and supports linearizability and sequential consistency of read operations. Furthermore, Aerospike chooses consistency over availability in the presence of network partitions. Therefore, during certain complex situations involving network related failures, some or all of the data may not be available for access. These guarantees have been validated externally by Jepsen.
Situations where Relaxed Consistency is beneficial
Aerospike originally provided two strong consistency read modes, linearize and session. In both these modes, Aerospike reads a record only from the master node housing the record’s partition. Relaxing this to allow reads from replicas could be beneficial in certain situations, as follows:
Unexpected node crashes during in-progress transactions (causing timeouts). This is pertinent since the current scheme of reading from master partitions would require the reads to wait until these master partitions are safely transferred to another node in the cluster. The master handoff process can take up to 1.8 seconds by default and the upper limit for a specific configuration may be higher. While it is acceptable to let writes wait until the transfer happens, reads are another story. For example, when a user is playing a game and the system requires access to parameters that were just stored in the database, it is imperative that the read return promptly so that the game can continue uninterrupted. In such a use case, the system could return the currently accessible value (even if it is a bit outdated) rather than wait for over a second to get the correct value.
Node splits across two racks spanning datacenters or availability zones. In high availability use cases, systems are run by splitting nodes from one cluster into two racks and locating the two racks in different data centers or cloud availability zones. Always reading from the master on a two rack system will incur 50% of the reads from any application running on one rack to access the database node in the other (more distant) rack thus creating additional read latency for 50% of the requests. Furthermore, cross-rack requests in cloud-based environments with racks in different availability zones incur data transfer charges that can be very expensive. Given that typical workloads contain a larger proportion of reads than writes, always allowing applications to read from the local rack could pay great dividends in terms of increasing performance as well as significantly lower data transfer charges.
As important as it is for Aerospike to support strong consistency for situations like the core banking case described above, it is equally important for the system to support relaxed consistency levels for other use cases, where reading a slightly older (stale but committed) value may be acceptable, assuming the system can improve its availability or performance or both. For example, even in split-brain situations where blocking writes is necessary to ensure no data loss, there could be reasonable options for allowing certain reads to proceed for increased availability.
All Client Read Consistency Modes
In this release, Aerospike adds two relaxed consistency modes for reads for use with namespaces configured to operate in strong consistency mode. The first allows reads from replicas and the second also allows reads from partitions that could be unavailable for writes due to network level failures causing split-brains or multiple nodes to fail. The four client read consistency modes are:
Linearize – allows reads only from master. This is the strictest read mode and linearizes reads and writes on every record.
Session (default) – allows reads only from master. All reads and writes from the same session are ordered.
Allow replica (new) – allows read from the master or any replica. This could violate session consistency in rare cases.
Allow unavailable (new) – allows read from certain partitions even though the partition is unavailable for writes due to cascading network failures causing split-brain or worse.
You can find more information about strong consistency in Aerospike here.
The New Relaxed Consistency Modes
We will now describe below the two new modes, “allow replica” and “allow unavailable,” in more detail.
Allow replica:
Reads from master any time, or from any replica, but only if the replica contains all current data and is not undergoing data migration. If the replica is not current, as indicated by the replica’s version number, the request is proxied to the master.
A master node that has rejoined the cluster after breaking way earlier has only a subset of the data and will access versions of the same partitions located elsewhere in the cluster in order to resolve duplicates before responding to the client.
If the record on a replica is flagged as not fully replicated (i.e. “dirty”), the read is proxied to the master.
Typically, in a stable cluster, the replicas will have the current data (without ongoing migrations), thus requiring no additional duplicate resolution steps.The allow replica read mode can cause session consistency violations but these situations will be very rare. In the three node cluster (see Figure 1 below), node A separates from the cluster (using a one-way network fault) while nodes B and C continue.
For a short period, A continues to receive heartbeats from B and C and thinks it is still the master but nodes B and C are not getting A’s heartbeats and have kicked A out of the cluster. Given that both nodes A and B had the current data at the time of the network fault, the client considers both of them valid for communication. Therefore in the uncertainty period when both A and B are considering themselves as master, the client could try to read from A and on failure retry the read on B and get the value RV2 followed by reading again from A and get the value RV1 (this happens because for a short period the client’s partition map has A as master and B as replica even though B has taken over master status). Reading RV2 followed by RV1 in the same client is a violation of session (sequential) consistency.
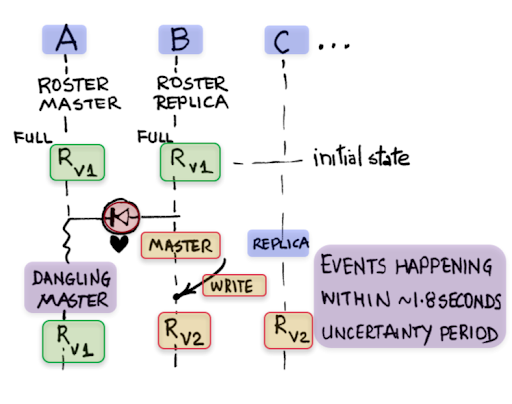
Figure 1: Session consistency violation caused by read mode allow replica
Allow unavailable:
When a partition is deemed as available for writes, this follows all of the same rules described above for the “allow replica” read mode
When a partition is deemed as unavailable for writes, reads are still allowed
If the record is flagged as not fully replicated, the read is disallowed, i.e., no dirty reads
Since the partitions can stay unavailable for longer periods of time than the brief intervals during master handoff, there is a higher likelihood for stale reads (i.e., violation of session consistency) in this mode. There are more cases where reads are allowed in this case than in the other cases.
Let us consider an interesting case where a cluster splits into two sub-clusters of even size (Figure 2). Let us consider a partition P that happens to have node A as the master and node D as the replica. If the cluster splits into two even sub-clusters, with nodes A, B, C in one sub-cluster and the rest of the nodes in the other. In this case, both A and D will have full partitions but the client may be able to read repeatedly from D and A even though D is unavailable (the window is approx. 1.8 seconds by default). Such cases are more likely and therefore there will be more chances of session consistency violations on the “allow unavailable” read consistency mode.
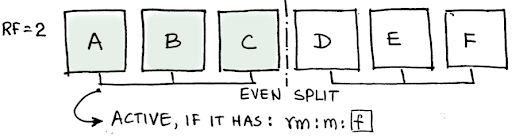
Figure 2: Session consistency can be violated in more cases in allow unavailable mode
Note that in all of these consistency modes, dirty reads are not allowed, i.e. only committed data is read. There is definitely an overhead that is incurred by the system in terms of proxying requests that might result when the initial request ends up in a node that only has a subset of the data. Additionally, reads causing duplicate resolution will be slower and use more resources in a system that is already compromised by node and network failures. The following table summarizes the characteristics of the four read consistency modes.
Read consistency mode | Loss of writes | Stale read | Dirty read | Read Performance | Read availability during major network failures (e.g., split-brain) |
Linearize | No | No | No | Lowest | Low |
Session | No | No (within session) | No | High | Low |
Allow replica | No | Very rare | No | Higher than session with rack/zone locality, unless cluster not stable | Higher |
Allow unavailable | No | Rare | No | Same as allow replica with available partitions; Highest (no proxying or duplicate resolution) if unavailable | Highest |
Table 1: Read consistency modes
Finally, it is important to carefully consider if certain read consistency violations are acceptable for your application before using these relaxed consistency modes.
Useful links:
4.5.2 Release Notes
Product pages:
Relaxed Strong Consistency Reads. (Enterprise Only)
Solution Briefs: System of Record – solution brief
Additional resources
For a deeper understanding and more insights, explore these additional resources.
See more
Blog
KV cache tiering: Why GPU memory alone won't scale your LLM app
Read more
Blog
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS
Read more
Blog
Determining the best machine learning and AI databases
Read more
Blog