Every AI/ML project starts with the singular goal of creating the most accurate model within the shortest amount of time. However, that hope is quickly dashed as soon as you get around to building your training pipeline at scale to work with vast amounts of data. No matter how optimized your algorithms are or the fact that you use GPUs, data loads are IO constrained by the choice of your database, and hence the end-to-end latency of the pipeline will be severely impacted.
As you read along, here are a few key points to keep in mind:
Traditional HDD based systems are not suitable for training, which is very IO intensive due to complex transformations that are involved during data preparation
Training is not a one time process. Trends and patterns in the data keep changing rapidly, hence models need to be retrained to address drift issues to continually improve the performance in production
Per a study by Micron, AI Training workloads require 6 times more DRAM and two times more SSDs.
Data scientists often experiment with thousands of models, and speeding up the process has significant business implications.
In a nutshell, the more time the data science team spends on model training, the less business value the team adds because no value is created until that model is deployed in production. It’s not just the training time, but the inference time also has a significant impact on the business, especially when you consider time-critical use cases such as fraud detection, risk analysis, etc. Any storage architecture that you choose for AI/ML must satisfy low latency and high throughput reads and writes, while not blowing the budget at the same time. So, how can Aerospike help you?
How Aerospike Technology supports AI/ML
Aerospike is a highly scalable NoSQL database and its hybrid memory architecture makes it an ideal database for AI/ML applications. It is typically deployed into real-time environments managing terabyte to petabyte data volumes and supports millisecond read and write latencies. It leverages bleeding-edge storage innovations such as PMem or persistent memory from best of breed hardware companies such as HPE and Intel. By storing indexes in DRAM, and data on persistent storage (SSD) and read directly from disk, Aerospike provides unparalleled speed and cost-efficiency demanded by an AI/ML pipeline at scale. It can be deployed alongside other scalable distributed software such as Kafka, Presto, Spark, etc. via the Aerospike Connect product line for data analysis.
Options to Accelerate your AI/ML Pipeline
From here on, we will explore a few options that you can choose from for your Aerospike deployment to accelerate your AI/ML pipeline.
Several Aerospike customers have been using Aerospike Connect for Spark in conjunction with our database to accelerate Apache Spark-based ETL pipelines. Aerospike’s efficient use of DRAM, SSD, and PMem offer Spark users high performance and cost-efficient storage for large volumes of real-time data. The Spark connector allows users to parallelize work on a massive scale by leveraging up to 32,768 Spark partitions to read data from an Aerospike namespace storing up to 32 billion records per namespace per node across 4096 partitions.
To put it in perspective, if you have a 256 node Aerospike cluster, which is the maximum allowed, you would be looking at a whopping 140 trillion objects. Aerospike will scan its partitions independently and in parallel; such support, when combined with Spark workers, enables Spark users to rapidly process large volumes of Aerospike data. Just to cite a case study, an Aerospike customer in the Ad-Tech space was harnessing data from millions of users across their digital assets to create a 360-degree customer profile to improve their targeting capability. The customer was able to maximize the ROI on their previously sub-optimally utilized Spark cluster. Consequently, it also enabled them to significantly reduce the training time for their ML models, which allowed them to increase the frequency of retraining to improve model accuracy. The customer was able to reduce the execution time of a Spark job processing over 200TB of data by 80%, from 12 to 2.5 hours. Furthermore, by using the Aerospike database as the system of record and selectively loading data into Spark, they were able to eliminate the need to copy 100’s of terabytes to other analytics systems. This helped them significantly with compliance and cost reduction. This architecture can be extended to other AI/ML applications, and hence we have developed a blueprint (see figure 1) for AI/ML.
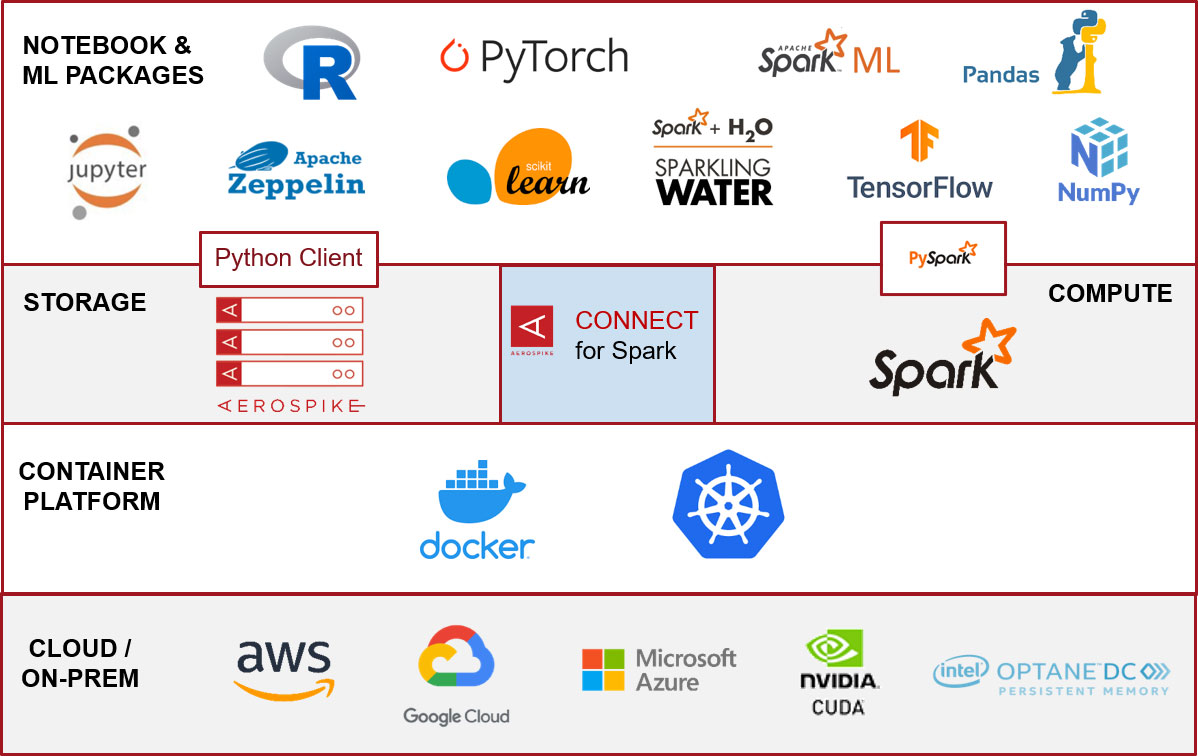
Figure 1: Aerospike Blueprint for AI/ML
It allows Data Science teams to load data from Aerospike into a Spark DataFrame in a massively parallel manner, so that they can bring to bear various Spark supported AI/ML libraries such as Pandas, NumPy, R, and frameworks such as TensorFlow, PyTorch, etc. Python is extensively used by data scientists looking to prep, process, and analyze data for analytics and machine learning use cases. The PySpark interface makes model development a breeze using Python. If you are interested, see the Aerospike Spark Python notebook to explore:
Reading data from Aerospike into a Spark DataFrame
Visualizing data
Writing state information into Aerospike DB, which serves as a state store
Preparing data using Spark APIs
Training a model using SparkML
The advantage of the above approach is that you can use the same platform for data preparation and model creation, and progress from POC to production fairly rapidly. Similarly, you can extend the blue-print to H2O Sparkling Water and Scikit-learn as well. Both Spark and Aerospike can be deployed using Kubernetes into major public cloud environments.
Figure 2 shows how you can accelerate the training time. It shows a training pipeline that uses Aerospike as the system of record to store 100’s of terabytes of transactional data. The data is loaded into Spark via the Spark connector at scale as described in the aforementioned case study for pre-processing. A data scientist can then explore the data, which would later be used for model training, using Jupyter and Python libraries such as matplotlib. They can also launch pre-processing jobs using SparkSQL and the Spark Connector as needed. The pre-processed data can then be made available to a Spark supported AI/ML platform such as TensorFlow, etc, via a Spark DataFrame, which may need to be converted to the platform-native format. Additionally, pre-processed data can be persisted into Aerospike for future use and the model states could be written to Aerospike as well for low latency lookups.
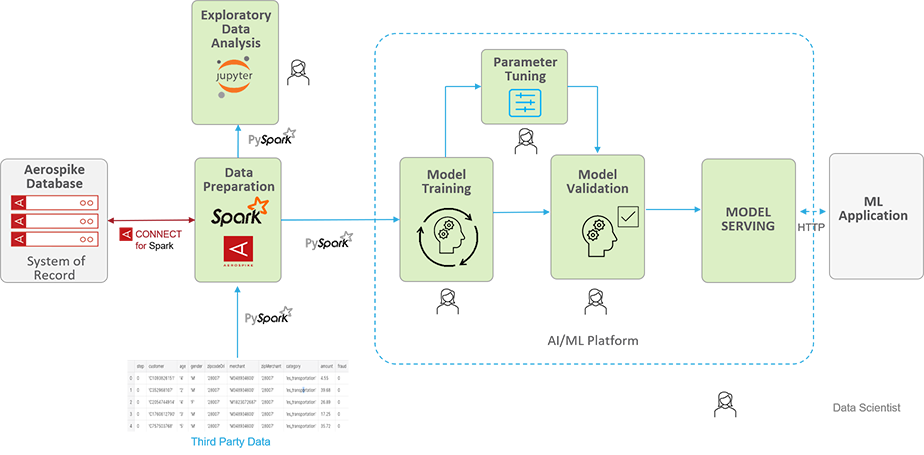
Figure 2: How Aerospike accelerates AI/ML training time.
There are Aerospike customers that currently use Aerospike DB for high-velocity ingestion at the edge in IIoT use cases because it supports millions of IOPS. This allows for the application of backpressure so that the downstream AI/ML platform can keep pace with ingestion rates as high as millions of events per second or so. Additionally, you can stream data to your Spark cluster by using Kafka as a streaming source and load it into a streaming DataFrame. This will allow you to bring to bear your Spark supported AI/ML library or framework for creating a robust inference pipeline (see figure 3).
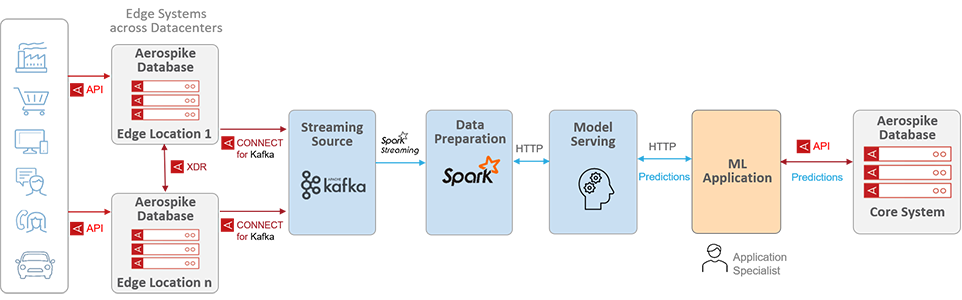
Figure 3: Creating a robust inference pipeline with Aerospike, Spark, and Kafka
With its recently announced multi-site clustering capability, Aerospike offers a globally consistent view of data to geographically distributed data science teams. These teams can then merge (join) this data with local datasets for localized training and model creation for better generalization.
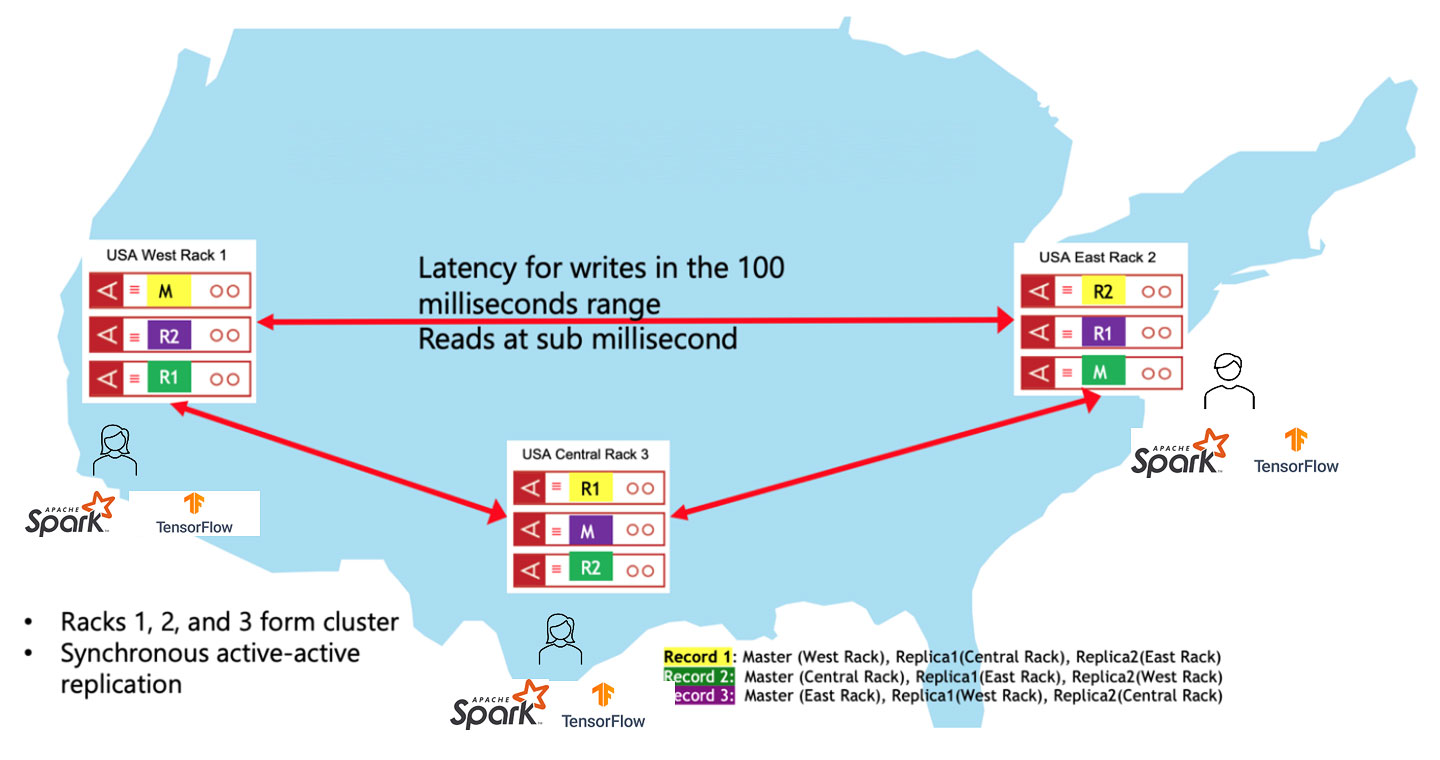
Figure 4: Aerospike offers consistent view of data across geographic regions
In conclusion, if you are looking to accelerate your AI/ML pipeline, look no further. Aerospike can help you build a low latency and high throughput pipeline, without blowing your budget.
Learn more: Feed Hungry AI Systems More Data, Faster & Efficiently