Aerospike Database Cross Datacenter Replication (XDR) provides dynamic, fine-grained control for the replication of data across geographically separate clusters. It can be used to build globally distributed applications with low latency reads and writes at each data center, accessing the data that is meaningful to each region while complying with data locality regulations.
The Aerospike XDR feature replicates data asynchronously between two or more clusters that are located at different, geographically distributed sites. A site can be a physical rack in a data center, an entire data center, an availability zone in a cloud region, or a cloud region. Each cluster can have its own dynamically defined list of destination clusters it should be shipping data to. This flexible configuration enables different deployment models.
Aerospike XDR deployment example topologies:
| Deployment Topology type | Example configuration |
|---|---|
One-way shipping cluster configuration
| One cluster in an availability zone in the AWS Amazon US West region configured to ship all of its data updates to a second cluster in a different availability zone also in US West Amazon West region. |
Two-way shipping cluster configuration
| A two-cluster system where each cluster is configured to ship all of its data updates to the other: e.g. the first cluster in Amazon US West region and the second in Amazon East region. In this case, applications can be configured to use either cluster for both reads/updates. |
Three-way shipping cluster configuration
| A three-cluster cross-cloud Active-Active system: e.g. one cluster in an Azure datacenter in the US West region, a second cluster in Amazon US Central region, and a third cluster on Google Cloud US East region. |
- Typically Active-Passive setup
- Second cluster commonly described as “hot standby”
- Typically characterized as Active-Active
- Typically characterized as Active-Active
XDR with expressions
Aerospike XDR has the ability to filter modified records from shipping to a destination using Expressions.
- Different filter expressions can be attached to each destination.
- Bin projections can be applied to the selected records.
- Enables distributed deployment models such as hub-and-spoke for large central processing clusters and smaller edge app-serving clusters.
With XDR with Expressions, all writes to a local Aerospike cluster will ship to its defined destination clusters with fine-grained controls at the namespace, set, record and bin level.
Aerospike XDR proxy – for configuration in containerized/cloud environments
Aerospike XDR Proxy addresses cross-datacenter situations where the source Aerospike cluster cannot get direct access to the nodes of the remote cluster. This includes most containerized environments, such as those launched via Kubernetes, but could be extended to cloud-based deployments in general, where a VPC/VPN containing both source and destination Aerospike clusters cannot be established. The XDR Proxy can be used to expose the destination Aerospike cluster as a service to the source cluster.
Configuration options with and without load balancers:
In Figure 1, the load balancer balances the traffic from the source cluster across multiple XDR proxy instances while providing isolation from direct internet access. The advantage of this approach is that a single IP address needs to be exposed to the internet.
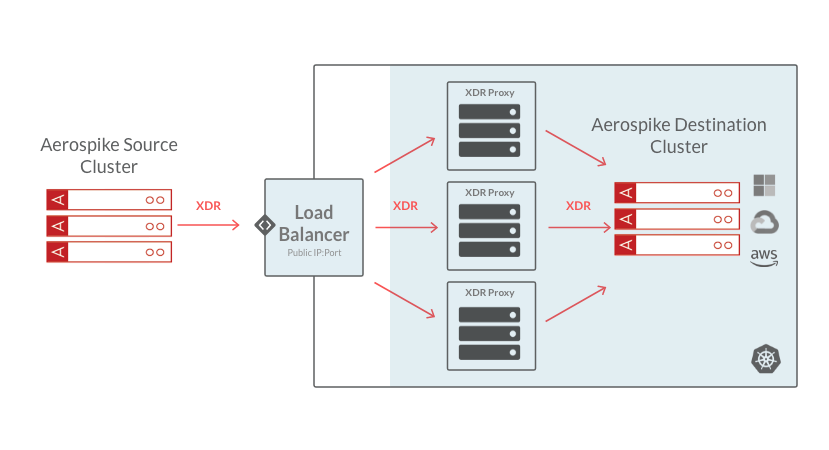 Figure 1
Figure 1
In Figure 2, the traffic from the source cluster is routed to several instances of the XDR Proxy. Load balancing is done by Aerospike here.
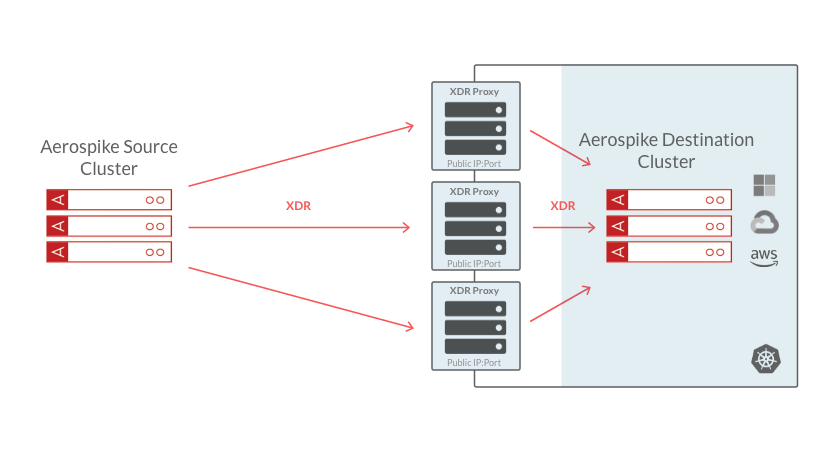 Figure 2
Figure 2



