Aerospikeテクノロジーが大規模展開に最適な理由
| キャッシュとDBの組み合わせ | メインフレーム | Aerospike | |
|---|---|---|---|
| スケールアップ | |||
| スケールアウト | |||
| 一貫性 | |||
| パフォーマンス | |||
| 予測可能なパフォーマンス | |||
| 信頼性 | |||
| 低TCO | |||
| 容易なデプロイ |
|
Aerospike Databaseの構成
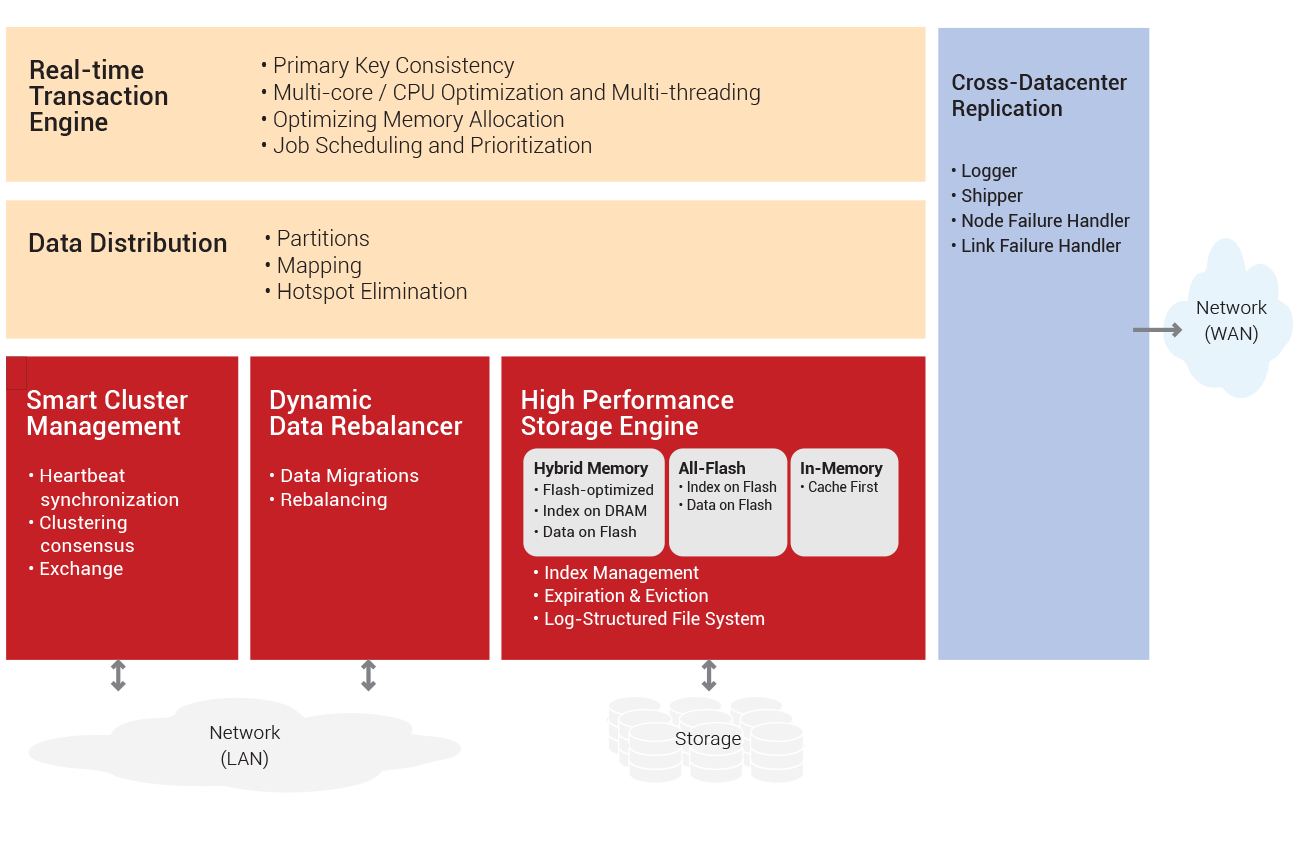
Aerospike Data Distributionにより、レコードのキーをサーバーノードに均等に分散させる、独自のデータ・パーティショニングが実行されます。データアクセス時のホットスポットを回避し、高度なスケーラビリティと耐障害性を実現します。Aerospikeは、インデックスとデータを同じサーバに配置することで、読み取りオペレーションやクエリ実行の際のノード間トラフィックの発生を回避します。
ノード間の均等データ分散のメリット:
- クラスタ全体でアプリケーションのワークロードが均等に分散されます。
- データベースのパフォーマンスが予測可能になります。
- クラスタのスケールアップとスケールダウンが容易になります。
- クラスタの動的再構成とそれに伴うデータのリバランシングがシンプルになり、中断することなく効率的に行われます。
決定論的に行われるパーティションの割り当てにより、以下が可能となります。
- 各ノードが同じパーティションマップを計算可能
- マスターパーティションとそのレプリカの均等分散
- パーティション移動の最小化
容易にプログラムできるリストやマップなどのデータ構造により、パフォーマンスの向上とフィールド値のインデックス検索が可能になります。
リアルタイム・トランザクションエンジンは、リクエストに基づきデータの読み書きを担うと同時に、一貫性と分離性を担保します。その際、同期/非同期レプリケーション、特定のノードが利用できなくなった場合の別のノードへのリクエスト、またノードが再度クラスタに追加された後の矛盾/重複の解決を行います。
マルチコアシステム
CPUコア個別ではなく、CPUソケット毎に複数のスレッドをグループ化することで、NUMAリージョンを跨いで共有されるデータを削減し、レイテンシを改善します。
コンテキスト・スイッチ(オフロード)
一般的なコンテキストスイッチのコスト発生を回避します。いくつかの処理は、CPUリソースを開放することなくネットワーク・リスナー・スレッドそのもので実行されます(システムはコアと同数のネットワークリスナースレッドを作成します)。
メモリの割り当て
メモリをデフラグメントする必要性を最小限に抑制し、アプリケーションやランタイム環境の負荷を緩和します。インデックスがRAMに留まり続けることで、システムリソースが有効活用されます。Namespaceによってデータオブジェクトが同じ領域内にグループ化されることで、断片化が最小限に抑制されます。その結果、オブジェクトの作成、アクセス、変更、削除のパターンが長期的に最適化されます。
データ構造のデザイン
複数のロックを維持することなく、インデックスツリーに対して安全な同時読み取り、書き込み、削除アクセスが可能です。これは、ツリーの各要素が個別にリファレンスカウントとそのロック機能を備えているためです。その結果、インデックスツリーのような入れ子のデータ構造へのアクセスが可能になると同時に、各レベルで複数のロック確保が関与しないため、パーティション間の競合を軽減できます。
スケジューリングと優先順位付け
基本的なキーバリューストア・オペレーションに加えて、Aerospikeはバッチクエリ、スキャン、セカンダリインデックス・クエリをサポートします。スループットやフェアネスを通じた優先順位付けは、タイプ、必要とされるCPUパワー、生成される負荷のコントロールに基づく、ジョブのパーティショニングによって行われます。
クロスデータセンター・レプリケーション(XDR) は、アクティブ・アクティブ、アクティブ・パッシブ、チェーン、スター、マルチホップ型の構成をサポートします。
負荷シェアリング
ノードに障害が発生すると、他のすべてのノードがその障害を検知し、未実行の作業を代わりに引き継ぎます。このスキームは水平拡張でき、ノードを追加することで増加するレプリケーション負荷を処理することができます。
データ送信
データ送信の対象となるNamespaceやSetのレベル設定がサポートされています。送信されるデータ、特にホットキーの場合、送信量を削減するため、最適化が行われます。データ圧縮もサポートされています(特に文字列型やBLOB型データでレコードが1KBよりも大きい場合にメリットがあります)。
リモートクラスタ管理
リモートクラスタの状態変更の継続的な追跡、リモートクラスタのすべてのノードへの接続、コネクション・プールの維持、通常のクライアントと同様にすべてのロールの実行が可能です。ノード数に比例したデータ送受信モデルにより、異なるサイズのクラスタ間でデータ送受信が可能になります。1つのノードが稼働可能である限り新たな変更が送信され続け、容易にノードの追加や減少に適応します。
パイプラインの活用
データセンター間のデータ送信において、Aerospikeは非同期型のパイプライン化スキームを使用します。送信元のクラスタでは、各ノードが送信先のクラスタのすべてのノードと通信します。送信先に書き込まれる複数のレコードが、コネクション上で待機することになります。Aerospikeは、このパイプライン化スキームによって、高レイテンシとなるWAN経由上で高スループットを実現しています。
- + データ配置
Aerospike Data Distributionにより、レコードのキーをサーバーノードに均等に分散させる、独自のデータ・パーティショニングが実行されます。データアクセス時のホットスポットを回避し、高度なスケーラビリティと耐障害性を実現します。Aerospikeは、インデックスとデータを同じサーバに配置することで、読み取りオペレーションやクエリ実行の際のノード間トラフィックの発生を回避します。
ノード間の均等データ分散のメリット:
- クラスタ全体でアプリケーションのワークロードが均等に分散されます。
- データベースのパフォーマンスが予測可能になります。
- クラスタのスケールアップとスケールダウンが容易になります。
- クラスタの動的再構成とそれに伴うデータのリバランシングがシンプルになり、中断することなく効率的に行われます。
決定論的に行われるパーティションの割り当てにより、以下が可能となります。
- 各ノードが同じパーティションマップを計算可能
- マスターパーティションとそのレプリカの均等分散
- パーティション移動の最小化
容易にプログラムできるリストやマップなどのデータ構造により、パフォーマンスの向上とフィールド値のインデックス検索が可能になります。
- + リアルタイム・トランザクションエンジン
リアルタイム・トランザクションエンジンは、リクエストに基づきデータの読み書きを担うと同時に、一貫性と分離性を担保します。その際、同期/非同期レプリケーション、特定のノードが利用できなくなった場合の別のノードへのリクエスト、またノードが再度クラスタに追加された後の矛盾/重複の解決を行います。
マルチコアシステム
CPUコア個別ではなく、CPUソケット毎に複数のスレッドをグループ化することで、NUMAリージョンを跨いで共有されるデータを削減し、レイテンシを改善します。
コンテキスト・スイッチ(オフロード)
一般的なコンテキストスイッチのコスト発生を回避します。いくつかの処理は、CPUリソースを開放することなくネットワーク・リスナー・スレッドそのもので実行されます(システムはコアと同数のネットワークリスナースレッドを作成します)。
メモリの割り当て
メモリをデフラグメントする必要性を最小限に抑制し、アプリケーションやランタイム環境の負荷を緩和します。インデックスがRAMに留まり続けることで、システムリソースが有効活用されます。Namespaceによってデータオブジェクトが同じ領域内にグループ化されることで、断片化が最小限に抑制されます。その結果、オブジェクトの作成、アクセス、変更、削除のパターンが長期的に最適化されます。
データ構造のデザイン
複数のロックを維持することなく、インデックスツリーに対して安全な同時読み取り、書き込み、削除アクセスが可能です。これは、ツリーの各要素が個別にリファレンスカウントとそのロック機能を備えているためです。その結果、インデックスツリーのような入れ子のデータ構造へのアクセスが可能になると同時に、各レベルで複数のロック確保が関与しないため、パーティション間の競合を軽減できます。
スケジューリングと優先順位付け
基本的なキーバリューストア・オペレーションに加えて、Aerospikeはバッチクエリ、スキャン、セカンダリインデックス・クエリをサポートします。スループットやフェアネスを通じた優先順位付けは、タイプ、必要とされるCPUパワー、生成される負荷のコントロールに基づく、ジョブのパーティショニングによって行われます。
- + クロスデータセンター・レプリケーション(XDR)
クロスデータセンター・レプリケーション(XDR) は、アクティブ・アクティブ、アクティブ・パッシブ、チェーン、スター、マルチホップ型の構成をサポートします。
負荷シェアリング
ノードに障害が発生すると、他のすべてのノードがその障害を検知し、未実行の作業を代わりに引き継ぎます。このスキームは水平拡張でき、ノードを追加することで増加するレプリケーション負荷を処理することができます。
データ送信
データ送信の対象となるNamespaceやSetのレベル設定がサポートされています。送信されるデータ、特にホットキーの場合、送信量を削減するため、最適化が行われます。データ圧縮もサポートされています(特に文字列型やBLOB型データでレコードが1KBよりも大きい場合にメリットがあります)。
リモートクラスタ管理
リモートクラスタの状態変更の継続的な追跡、リモートクラスタのすべてのノードへの接続、コネクション・プールの維持、通常のクライアントと同様にすべてのロールの実行が可能です。ノード数に比例したデータ送受信モデルにより、異なるサイズのクラスタ間でデータ送受信が可能になります。1つのノードが稼働可能である限り新たな変更が送信され続け、容易にノードの追加や減少に適応します。
パイプラインの活用
データセンター間のデータ送信において、Aerospikeは非同期型のパイプライン化スキームを使用します。送信元のクラスタでは、各ノードが送信先のクラスタのすべてのノードと通信します。送信先に書き込まれる複数のレコードが、コネクション上で待機することになります。Aerospikeは、このパイプライン化スキームによって、高レイテンシとなるWAN経由上で高スループットを実現しています。
スループットやレイテンシという性能特性だけでなく、大量のデータを保持し処理できるスケーラビリティ特性もDBMSとしての能力を決定づける大きな要素です。Aerospikeは、その基盤から、SSDテクノロジーを有効活用するための設計がなされています。その結果、1台のマシンでテラバイト規模のデータを管理しつつ、ミリ秒未満の高速アクセスが可能になりました。Aerospikeは、次の3種類のストレージ方式をサポートします:ハイブリッドメモリ、オールフラッシュ、インメモリ:
Aerospikeはハイブリッドモデルを実装しています。このモデルでは、インデックスはメモリ上に格納され(しかし永続化はされない)、データは永続ストレージであるSSDのみに格納され、直接SSDから読み取りされます。インデックスへのアクセスではディスクへのアクセスが不要なため、予測可能なパフォーマンスが可能になります。Aerospikeは、大きなブロックの書き込みによるコピーオンライト方式を採用し、同じ場所への更新を回避することでSSDデバイスの耐久性を向上させています。アプリケーションからの確認を受け取る前に、データをディスクへ書き込むことができます。SSDへのアクセスは、すべてのノードとそのノードに内蔵されたフラッシュ(SSD)ドライブの両方に均一に保存されているデータに対して、極めて高いレベルの並列処理で実行され、負荷変化に伴う再構成によるホットスポットを排除します。
この方式は、ハイブリッドメモリを拡張するもので、従来型のリレーショナルシステムが最良の選択肢だと思われる領域においても、Aerospikeは信頼性、一貫性、使いやすさを提供します。この方式が選択肢に追加されたことで、これまでHBaseやHDFSが最良の選択肢だと考えられていた大規模レコードシステムにも適したデプロイ戦略を提供可能となりました。オールフラッシュは、Aerospikeのハイブリッドメモリを拡張し、より広範なユースケースのサポートを実現します。この方式では、極めて膨大な数(数千億規模)の小さなオブジェクト(1,000バイト未満)に適しています。これは、個々の挙動を個々のデータベースの要素として保存するアーキテクチャ、あるいはGDPR形式のデータレイアウトのためにデータ要素を分離する必要のあるアーキテクチャにおいて一般的な方法です。
インメモリ・ストレージサブシステム
Aerospikeのインメモリ・ストレージアーキテクチャでは、すべてのインデックスとデータセット全体が常時DRAMに格納されており、データのみが永続ストレージ(HDD等の回転式ディスクドライブを使用可能)にバックアップされています。このため、アプリケーションの読み取りはすべてDRAMから実行されます。しかしながら、書き込みはまずインメモリバッファに対して行われ、続いて永続ストレージ(HDDまたはSSD)へと実行されます。さらに、強力な一貫性モードでは、アプリケーションがあらゆる書き込みを永続ストレージに対して直接実行します。
Aerospikeのデータ・リバランシング・メカニズムによって、トランザクション量はすべてのノードへ均等分散されます。このメカニズムは、リバランシング中に、ノードに障害が発生した場合に堅牢性を発揮します。システムは継続的な可用性を確保する設計が為されているため、データのリバランシングがクラスタの挙動に影響を及ぼすことはありません。
メリット
- スケーラブルなシェアード・ナッシング環境でトランザクションのシンプルさを最適化します。
- クラスタは、アクセスの高い時であっても、オペレータが介在することなく自己修復します。
- キャパシティ・プランニングとシステム監視機能により、予期しない障害の発生によるサービスの停止を最小現に抑制します。
- ハードウェアのキャパシティ構成とプロビジョニング、さらにレプリケーション/同期ポリシーにより、ユーザーはデータベースの障害から保護されます。
あるノードから別のノードへのレコード移行プロセスは、マイグレーションと呼ばれています。いかなるクラスタ構成の変更後にデータマイグレーションを行う目的は、各データパーティション内のデータの最新バージョンを、各々のマスターノードとレプリカノードに持つことです。
マイグレーションの最適化
Aerospikeは、次のようにマイグレーションを最適化します。
- 各ノードは、レコードが変更された場合のみを対象とします(ローリングアップグレードの際に特に有効です)。
- 同じパーティション内のレコードが変更されていない場合、マイグレーションは行いません。
- レコードへの部分的な書き込みが完了していることを確認するため、マイグレーション中に重複検証が行われます
自己修復型スマートクラスタマネージャは、クラスタへのシームレスなノードの追加と削除を担います。
ハートビート・サブシステム
ノード間で情報(クラスタ構成リスト中の各ノードのステータス)の保管と交換を行います。(ハートビートは、新しいノードの検索に使用されます)。
クラスタリング・サブシステム
コンセンサス用に現在のアクティブなクラスタ内のノードのメンバーシップ情報(ノード構成リスト)を保持します。
交換サブシステム
パーティションの状態を交換し、リバランシング・アルゴリズムを起動します。
- + ストレージエンジン
スループットやレイテンシという性能特性だけでなく、大量のデータを保持し処理できるスケーラビリティ特性もDBMSとしての能力を決定づける大きな要素です。Aerospikeは、その基盤から、SSDテクノロジーを有効活用するための設計がなされています。その結果、1台のマシンでテラバイト規模のデータを管理しつつ、ミリ秒未満の高速アクセスが可能になりました。Aerospikeは、次の3種類のストレージ方式をサポートします:ハイブリッドメモリ、オールフラッシュ、インメモリ:
Aerospikeはハイブリッドモデルを実装しています。このモデルでは、インデックスはメモリ上に格納され(しかし永続化はされない)、データは永続ストレージであるSSDのみに格納され、直接SSDから読み取りされます。インデックスへのアクセスではディスクへのアクセスが不要なため、予測可能なパフォーマンスが可能になります。Aerospikeは、大きなブロックの書き込みによるコピーオンライト方式を採用し、同じ場所への更新を回避することでSSDデバイスの耐久性を向上させています。アプリケーションからの確認を受け取る前に、データをディスクへ書き込むことができます。SSDへのアクセスは、すべてのノードとそのノードに内蔵されたフラッシュ(SSD)ドライブの両方に均一に保存されているデータに対して、極めて高いレベルの並列処理で実行され、負荷変化に伴う再構成によるホットスポットを排除します。
この方式は、ハイブリッドメモリを拡張するもので、従来型のリレーショナルシステムが最良の選択肢だと思われる領域においても、Aerospikeは信頼性、一貫性、使いやすさを提供します。この方式が選択肢に追加されたことで、これまでHBaseやHDFSが最良の選択肢だと考えられていた大規模レコードシステムにも適したデプロイ戦略を提供可能となりました。オールフラッシュは、Aerospikeのハイブリッドメモリを拡張し、より広範なユースケースのサポートを実現します。この方式では、極めて膨大な数(数千億規模)の小さなオブジェクト(1,000バイト未満)に適しています。これは、個々の挙動を個々のデータベースの要素として保存するアーキテクチャ、あるいはGDPR形式のデータレイアウトのためにデータ要素を分離する必要のあるアーキテクチャにおいて一般的な方法です。
インメモリ・ストレージサブシステム
Aerospikeのインメモリ・ストレージアーキテクチャでは、すべてのインデックスとデータセット全体が常時DRAMに格納されており、データのみが永続ストレージ(HDD等の回転式ディスクドライブを使用可能)にバックアップされています。このため、アプリケーションの読み取りはすべてDRAMから実行されます。しかしながら、書き込みはまずインメモリバッファに対して行われ、続いて永続ストレージ(HDDまたはSSD)へと実行されます。さらに、強力な一貫性モードでは、アプリケーションがあらゆる書き込みを永続ストレージに対して直接実行します。
- + ダイナミックデータリバランサー
Aerospikeのデータ・リバランシング・メカニズムによって、トランザクション量はすべてのノードへ均等分散されます。このメカニズムは、リバランシング中に、ノードに障害が発生した場合に堅牢性を発揮します。システムは継続的な可用性を確保する設計が為されているため、データのリバランシングがクラスタの挙動に影響を及ぼすことはありません。
メリット
- スケーラブルなシェアード・ナッシング環境でトランザクションのシンプルさを最適化します。
- クラスタは、アクセスの高い時であっても、オペレータが介在することなく自己修復します。
- キャパシティ・プランニングとシステム監視機能により、予期しない障害の発生によるサービスの停止を最小現に抑制します。
- ハードウェアのキャパシティ構成とプロビジョニング、さらにレプリケーション/同期ポリシーにより、ユーザーはデータベースの障害から保護されます。
あるノードから別のノードへのレコード移行プロセスは、マイグレーションと呼ばれています。いかなるクラスタ構成の変更後にデータマイグレーションを行う目的は、各データパーティション内のデータの最新バージョンを、各々のマスターノードとレプリカノードに持つことです。
マイグレーションの最適化
Aerospikeは、次のようにマイグレーションを最適化します。
- 各ノードは、レコードが変更された場合のみを対象とします(ローリングアップグレードの際に特に有効です)。
- 同じパーティション内のレコードが変更されていない場合、マイグレーションは行いません。
- レコードへの部分的な書き込みが完了していることを確認するため、マイグレーション中に重複検証が行われます
- + 自己修復型スマートクラスタ
自己修復型スマートクラスタマネージャは、クラスタへのシームレスなノードの追加と削除を担います。
ハートビート・サブシステム
ノード間で情報(クラスタ構成リスト中の各ノードのステータス)の保管と交換を行います。(ハートビートは、新しいノードの検索に使用されます)。
クラスタリング・サブシステム
コンセンサス用に現在のアクティブなクラスタ内のノードのメンバーシップ情報(ノード構成リスト)を保持します。
交換サブシステム
パーティションの状態を交換し、リバランシング・アルゴリズムを起動します。
Aerospike Databaseの構成
データ配置
Aerospike Data Distributionにより、レコードのキーをサーバーノードに均等に分散させる、独自のデータ・パーティショニングが実行されます。データアクセス時のホットスポットを回避し、高度なスケーラビリティと耐障害性を実現します。Aerospikeは、インデックスとデータを同じサーバに配置することで、読み取りオペレーションやクエリ実行の際のノード間トラフィックの発生を回避します。
ノード間の均等データ分散のメリット:
- クラスタ全体でアプリケーションのワークロードが均等に分散されます。
- データベースのパフォーマンスが予測可能になります。
- クラスタのスケールアップとスケールダウンが容易になります。
- クラスタの動的再構成とそれに伴うデータのリバランシングがシンプルになり、中断することなく効率的に行われます。
決定論的に行われるパーティションの割り当てにより、以下が可能となります。
- 各ノードが同じパーティションマップを計算可能
- マスターパーティションとそのレプリカの均等分散
- パーティション移動の最小化
容易にプログラムできるリストやマップなどのデータ構造により、パフォーマンスの向上とフィールド値のインデックス検索が可能になります。
リアルタイム・トランザクションエンジン
リアルタイム・トランザクションエンジンは、リクエストに基づきデータの読み書きを担うと同時に、一貫性と分離性を担保します。その際、同期/非同期レプリケーション、特定のノードが利用できなくなった場合の別のノードへのリクエスト、またノードが再度クラスタに追加された後の矛盾/重複の解決を行います。
マルチコアシステム
CPUコア個別ではなく、CPUソケット毎に複数のスレッドをグループ化することで、NUMAリージョンを跨いで共有されるデータを削減し、レイテンシを改善します。
コンテキスト・スイッチ(オフロード)
一般的なコンテキストスイッチのコスト発生を回避します。いくつかの処理は、CPUリソースを開放することなくネットワーク・リスナー・スレッドそのもので実行されます(システムはコアと同数のネットワークリスナースレッドを作成します)。
メモリの割り当て
メモリをデフラグメントする必要性を最小限に抑制し、アプリケーションやランタイム環境の負荷を緩和します。インデックスがRAMに留まり続けることで、システムリソースが有効活用されます。Namespaceによってデータオブジェクトが同じ領域内にグループ化されることで、断片化が最小限に抑制されます。その結果、オブジェクトの作成、アクセス、変更、削除のパターンが長期的に最適化されます。
データ構造のデザイン
複数のロックを維持することなく、インデックスツリーに対して安全な同時読み取り、書き込み、削除アクセスが可能です。これは、ツリーの各要素が個別にリファレンスカウントとそのロック機能を備えているためです。その結果、インデックスツリーのような入れ子のデータ構造へのアクセスが可能になると同時に、各レベルで複数のロック確保が関与しないため、パーティション間の競合を軽減できます。
スケジューリングと優先順位付け
基本的なキーバリューストア・オペレーションに加えて、Aerospikeはバッチクエリ、スキャン、セカンダリインデックス・クエリをサポートします。スループットやフェアネスを通じた優先順位付けは、タイプ、必要とされるCPUパワー、生成される負荷のコントロールに基づく、ジョブのパーティショニングによって行われます。
クロスデータセンター・レプリケーション(XDR)
クロスデータセンター・レプリケーション(XDR)は、アクティブ・アクティブ、アクティブ・パッシブ、チェーン、スター、マルチホップ型の構成をサポートします。
負荷シェアリング
ノードに障害が発生すると、他のすべてのノードがその障害を検知し、未実行の作業を代わりに引き継ぎます。このスキームは水平拡張でき、ノードを追加することで増加するレプリケーション負荷を処理することができます。
データ送信
データ送信の対象となるNamespaceやSetのレベル設定がサポートされています。送信されるデータ、特にホットキーの場合、送信量を削減するため、最適化が行われます。データ圧縮もサポートされています(特に文字列型やBLOB型データでレコードが1KBよりも大きい場合にメリットがあります)。
リモートクラスタ管理
リモートクラスタの状態変更の継続的な追跡、リモートクラスタのすべてのノードへの接続、コネクション・プールの維持、通常のクライアントと同様にすべてのロールの実行が可能です。ノード数に比例したデータ送受信モデルにより、異なるサイズのクラスタ間でデータ送受信が可能になります。1つのノードが稼働可能である限り新たな変更が送信され続け、容易にノードの追加や減少に適応します。
パイプラインの活用
データセンター間のデータ送信において、Aerospikeは非同期型のパイプライン化スキームを使用します。送信元のクラスタでは、各ノードが送信先のクラスタのすべてのノードと通信します。送信先に書き込まれる複数のレコードが、コネクション上で待機することになります。Aerospikeは、このパイプライン化スキームによって、高レイテンシとなるWAN経由上で高スループットを実現しています。
ストレージエンジン
スループットやレイテンシという性能特性だけでなく、大量のデータを保持し処理できるスケーラビリティ特性もDBMSとしての能力を決定づける大きな要素です。Aerospikeは、その基盤から、SSDテクノロジーを有効活用するための設計がなされています。その結果、1台のマシンでテラバイト規模のデータを管理しつつ、ミリ秒未満の高速アクセスが可能になりました。Aerospikeは、次の3種類のストレージ方式をサポートします:ハイブリッドメモリ、オールフラッシュ、インメモリ:
Aerospikeはハイブリッドモデルを実装しています。このモデルでは、インデックスはメモリ上に格納され(しかし永続化はされない)、データは永続ストレージであるSSDのみに格納され、直接SSDから読み取りされます。インデックスへのアクセスではディスクへのアクセスが不要なため、予測可能なパフォーマンスが可能になります。Aerospikeは、大きなブロックの書き込みによるコピーオンライト方式を採用し、同じ場所への更新を回避することでSSDデバイスの耐久性を向上させています。アプリケーションからの確認を受け取る前に、データをディスクへ書き込むことができます。SSDへのアクセスは、すべてのノードとそのノードに内蔵されたフラッシュ(SSD)ドライブの両方に均一に保存されているデータに対して、極めて高いレベルの並列処理で実行され、負荷変化に伴う再構成によるホットスポットを排除します。
この方式は、ハイブリッドメモリを拡張するもので、従来型のリレーショナルシステムが最良の選択肢だと思われる領域においても、Aerospikeは信頼性、一貫性、使いやすさを提供します。この方式が選択肢に追加されたことで、これまでHBaseやHDFSが最良の選択肢だと考えられていた大規模レコードシステムにも適したデプロイ戦略を提供可能となりました。オールフラッシュは、Aerospikeのハイブリッドメモリを拡張し、より広範なユースケースのサポートを実現します。この方式では、極めて膨大な数(数千億規模)の小さなオブジェクト(1,000バイト未満)に適しています。これは、個々の挙動を個々のデータベースの要素として保存するアーキテクチャ、あるいはGDPR形式のデータレイアウトのためにデータ要素を分離する必要のあるアーキテクチャにおいて一般的な方法です。
インメモリ・ストレージサブシステム
Aerospikeのインメモリ・ストレージアーキテクチャでは、すべてのインデックスとデータセット全体が常時DRAMに格納されており、データのみが永続ストレージ(HDD等の回転式ディスクドライブを使用可能)にバックアップされています。このため、アプリケーションの読み取りはすべてDRAMから実行されます。しかしながら、書き込みはまずインメモリバッファに対して行われ、続いて永続ストレージ(HDDまたはSSD)へと実行されます。さらに、強力な一貫性モードでは、アプリケーションがあらゆる書き込みを永続ストレージに対して直接実行します。
ダイナミックデータリバランサー
Aerospikeのデータ・リバランシング・メカニズムによって、トランザクション量はすべてのノードへ均等分散されます。このメカニズムは、リバランシング中に、ノードに障害が発生した場合に堅牢性を発揮します。システムは継続的な可用性を確保する設計が為されているため、データのリバランシングがクラスタの挙動に影響を及ぼすことはありません。
メリット
- スケーラブルなシェアード・ナッシング環境でトランザクションのシンプルさを最適化します。
- クラスタは、アクセスの高い時であっても、オペレータが介在することなく自己修復します。
- キャパシティ・プランニングとシステム監視機能により、予期しない障害の発生によるサービスの停止を最小現に抑制します。
- ハードウェアのキャパシティ構成とプロビジョニング、さらにレプリケーション/同期ポリシーにより、ユーザーはデータベースの障害から保護されます。
あるノードから別のノードへのレコード移行プロセスは、マイグレーションと呼ばれています。いかなるクラスタ構成の変更後にデータマイグレーションを行う目的は、各データパーティション内のデータの最新バージョンを、各々のマスターノードとレプリカノードに持つことです。
マイグレーションの最適化
Aerospikeは、次のようにマイグレーションを最適化します。
- 各ノードは、レコードが変更された場合のみを対象とします(ローリングアップグレードの際に特に有効です)。
- 同じパーティション内のレコードが変更されていない場合、マイグレーションは行いません。
- レコードへの部分的な書き込みが完了していることを確認するため、マイグレーション中に重複検証が行われます。
自己修復型スマートクラスタ
自己修復型スマートクラスタマネージャは、クラスタへのシームレスなノードの追加と削除を担います。
ハートビート・サブシステム
ノード間で情報(クラスタ構成リスト中の各ノードのステータス)の保管と交換を行います。(ハートビートは、新しいノードの検索に使用されます)
クラスタリング・サブシステム
コンセンサス用に現在のアクティブなクラスタ内のノードのメンバーシップ情報(ノード構成リスト)を保持します。
交換サブシステム
パーティションの状態を交換し、リバランシング・アルゴリズムを起動します。
Learn More







