
This is the second in a series of articles describing a simplified example of near real-time Ad Campaign reporting on a fixed set of campaign dimensions usually displayed for analysis in a user interface. The solution presented in this series relies on Kafka, Aerospike’s edge-to-core data pipeline technology, and Apollo GraphQL
Part 1: real-time capture of Ad events via Aerospike edge datastore and Kafka messaging.
Part 2: aggregation and reduction of Ad events leveraging Aerospike Complex Data Types (CDTs) for aggregation and reduction of Ad events into actionable Ad Campaign Key Performance Indicators (KPIs).
Part 3: describes how an Ad Campaign user interface displays those KPIs using GraphQL retrieve data stored in an Aerospike Cluster.

Data flow
Summary of Part 1
In part 1 of this series, we
used an ad event simulator for data creation
captured that data in the Aerospike “edge” database
pushed the results to a Kafka cluster via Aerospike’s Kafka Connector
Part 1 is the base used to implement Part 2
The use case — Part 2
The simplified use case for Part 2 consists of reading Ad events from a Kafka topic, aggregating/reducing the events into KPI values. In this case, the KPIs are simple counters, but in the real-world, these would be more complex metrics like averages, gauges, histograms, etc.
The values are stored in a data cube implemented as a Document or Complex Data Type CDT in Aerospike. Aerospike provides fine-grained operations to read or write one or more parts of a CDT in a single, atomic, database transaction.
The Aerospike record:
The Core Aerospike cluster is configured to prioritise consistency over availability to ensure that numbers are accurate and consistent for use with payments and billing. Or in other words: Money
In addition to aggregating data, the new value of the KPI is sent via another Kafka topic (and possible separate Kafka cluster) to be consumed by the Campaign Service as a GraphQL subscription and providing a live update in the UI. Part 3 covers the Campaign Service, Campaign UI and GraphQL in detail.
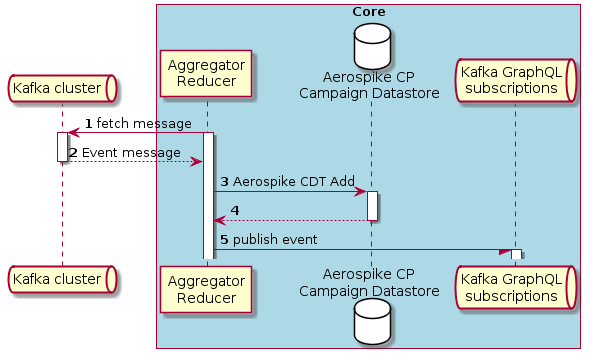
Aggregation/Reduction sequence
Companion code
The companion code is in GitHub. The complete solution is in the master branch. The code for this article is in the part-2 branch.Javascript and Node.js is used in each service although the same solution is possible in any languageThe solution consists of:
All of the service and containers in Part 1.
Aggregator/Reducer service — Node.js
Docker and Docker Compose simplify the setup to allow you to focus on the Aerospike specific code and configuration.
What you need for the setup
All the perquisites are described in Part 1.
Setup steps
To set up the solution, follow these steps. Because executable images are built by downloading resources, be aware that the time to download and build the software depends on your internet bandwidth and your computer.Follow the setup steps in Part 1. ThenStep 1. Checkout the part-2 branch$ git checkout part-2Step 2. Then run$ docker-compose upOnce up and running, after the services have stabilized, you will see the output in the console similar to this:

Sample console output
How do the components interact?
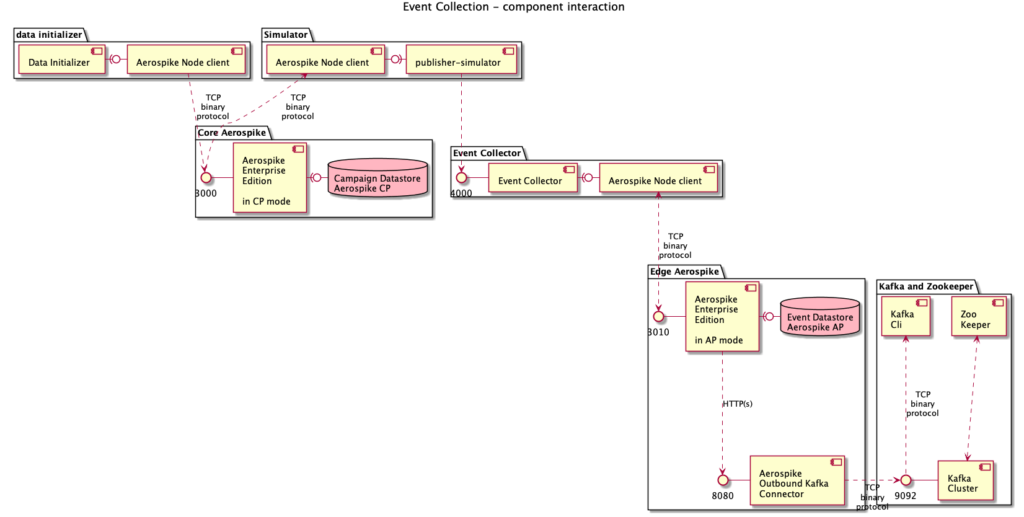
Component Interaction
Docker Compose orchestrates the creation of several services in separate containers:All of the services and containers in Part 1 with the addition of:Aggregator/Reducer aggregator-reducer — A node.js service to consume Ad event messages from the Kafka topic edge-to-core and aggregates the single event with the existing data cube. The data cube is a document stored in an Aerospike CDT. A CDT document can be a list, map, geospatial, or nested list-map in any combination. One or more portions of a CDT can be mutated and read in a single atomic operation. See CDT Sub-Context EvaluationHere we use a simple map where multiple discrete counters are incremented. In a real-world scenario, the datacube would be a complex document denormalized for read optimization.Like the Event Collector and the Publisher Simulator, the Aggregator/Reducer uses the Aerospike Node.js client. On the first build, all the service containers that use Aerospike will download and compile the supporting C library. The Dockerfile for each container uses multi-stage builds to minimise the number of times the C library is compiled.Kafka CLI kafkacli — Displays the KPI events used by GraphQL in Part 3
How is the solution deployed?
Each container is deployed using docker-compose on your local machine.Note: The aggregator-reducer container is deployed along with all the containers from Part 1.
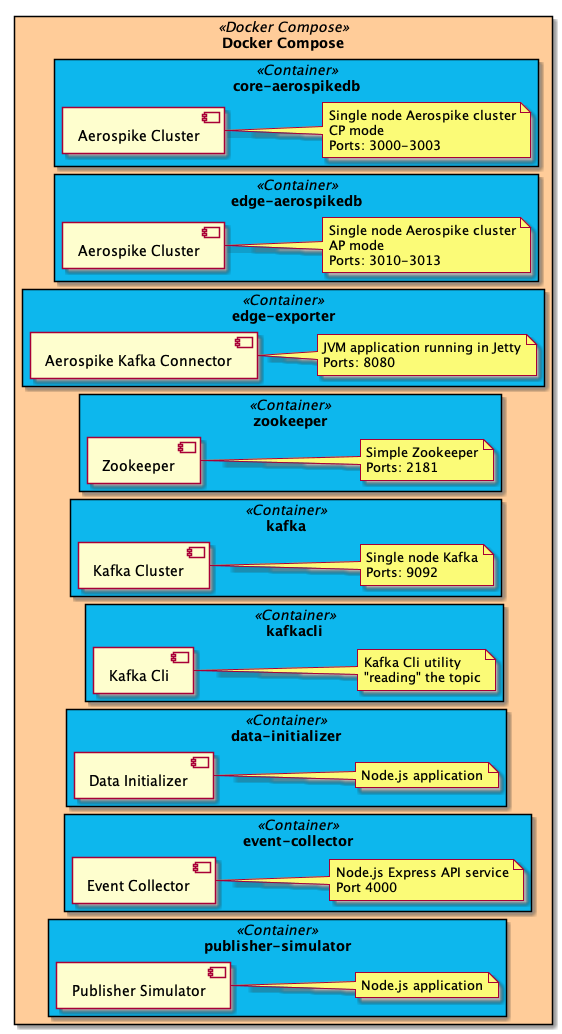
Deployment
How does the solution work?
The aggregator-reducer is a headless service that reads a message from the Kafka topic edge-to-core. The message is the whole Aerospike record written to edge-aerospikedb and exported by edge-exporter.The event data is extracted from the message and written to core-aerospikedb using multiple CDT operations in one atomic database operation.
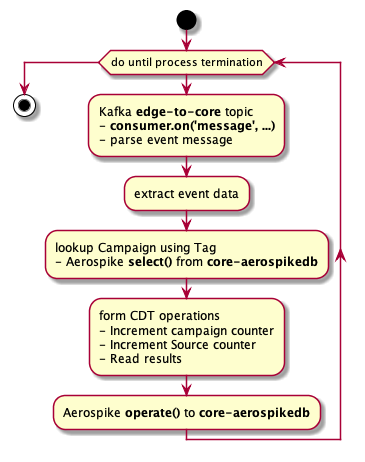
Aggregation flow
Connecting to Kafka
To read from a Kafka topic you need a Consumer and this is configured to read from one or more topics and partitions. In this example, we are reading message from one topic edge-to-core and this topic has only 1 partition.
Connecting to Kafka
Note that the addTopic() is called after the Consumer creation. This function attempts to add a topic to the consumer if unsuccessful it waits 5 seconds and tries again. Why do this? The Consumer will throw an error if the topic is empty and this code overcomes that problem.
Extract the event data
The payload of the message is a complete Aerospike record serialised as JSON.
These items are extracted:
1. Event value
2. Tag id
3. Event source
These values are used in the aggregation step.
Lookup Campaign Id using Tag
The Tag Id is used to locate the matching Campaign. During campaign creation, a mapping between Tags and Campaign is created, this example uses an Aerospike record where the key is the Tag id and the value is the Campaign Id, and in this case, Aerospike is used a Dictionary/Map/Associative Array.
Tag to Campaign mapping
Aggregating the Event
The Ad event is specific to a Tag and therefore a Campaign. In our model, a Tag is directly related to a Campaign and KPIs are collected at the Campaign level. In the real-world KPIs are more sophisticated and campaigns have many execution plans (line items).
Each event for a KPI increments the value by 1. Our example stores the KPIs in a document structure CDT in a bin in the Campaign record. Aerospike provides operations to atomically access and/or mutate sub-contexts of this structure to ensure the operation latency is ~1ms.
In a real-world scenario, events would be aggregated with sophisticated algorithms and patterns such as time-series, time windows, histograms, etc.
Our code simple increments the value KPI value by 1 using the KPI name as the ‘path’ to the value:
Accumulation
The new KPI value is incremented and the new value is returned. The magic of Aerospike ensures that the operation is Atomic and Consistent across the cluster with a latency of about 1 ms.
Publishing the new KPI
We could stop here and allow the Campaign UI and Service (Part 3) to poll the Campaign store core-aerospikedb to obtain the latest campaign KPIs — this is a typical pattern.
A more advanced approach is to stimulate the UI whenever a value has changed or at a specified frequency. While introducing new technology and challenges, this approach offers a very responsive UI presenting up to the second KPI values to the user.
The SubScriptionEventPublisher uses Kafka as Pub-Sub to publish the new KPI value for a specific campaign on the topic subscription-events. In Part 3 the campaign-service receives this event and publishes it as a GraphQL Subscription
Review
Part 1 of this series describes:
creating mock Campaign data
a publisher simulator
an event receiver
an edge database
an edge exporter
This article (Part 2) describes the aggregation and reduction of Ad events into Campaign KPIs using Kafka as the messaging system and Aerospike as the consistent data store.
Part 3 describes the Campaign service and Campaign UI for a user to view the Campaign KPIs in near real-time.
Disclaimer
This article, the code samples, and the example solution are entirely my own work and not endorsed by Aerospike or Confluent. The code is PoC quality only and it is not production strength and is available to anyone under the MIT License.


