A Journey of a Thousand Miles: Aerospike 3.8 Supercharges Cross Datacenter Replication (XDR)
A Journey of a Thousand Miles Begins…
… in an Amazon Web Services (AWS) data center in Boardman, Oregon, a part of the US-West region of AWS, where client machines write hundreds of thousands of records every second to an Aerospike cluster. This is the story of how Aerospike 3.8’s improved Cross Datacenter Replication (XDR) keeps step when replicating this sizable write load to another Aerospike cluster in Frankfurt, Germany in the EU (European Union) region of AWS, some 5,000 miles away.
The Latency Challenge
The most unfortunate fact of life regarding transatlantic round trips is seat pitch (for humans) and network latency (for data). Let’s take a look at the network round-trip time between our two data centers. For easier readability, we’ve replaced the IP addresses in Boardman and Frankfurt by 1.2.3.4 and 5.6.7.8, respectively:
ubuntu@ip-1-2-3-4:~$ ping 5.6.7.8
PING 5.6.7.8 (5.6.7.8) 56(84) bytes of data.
64 bytes from 5.6.7.8: icmp_seq=1 ttl=50 time=156 ms
64 bytes from 5.6.7.8: icmp_seq=2 ttl=50 time=156 ms
^C
--- 5.6.7.8 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1002ms
rtt min/avg/max/mdev = 156.487/156.494/156.505/0.322 msThat’s 156 ms between sending a message from Boardman to Frankfurt, and receiving Frankfurt’s response back in Boardman.
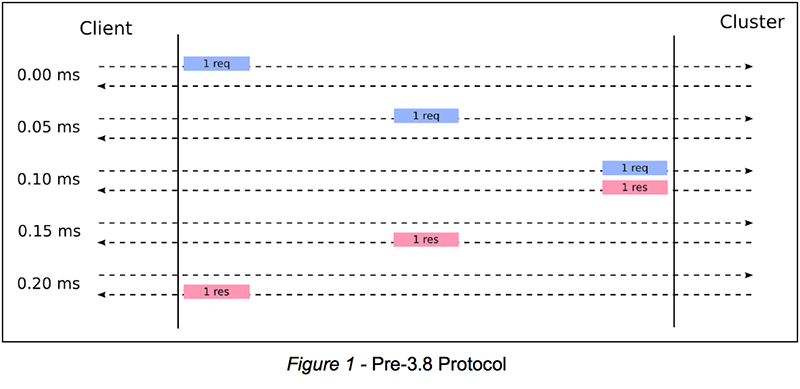
The Aerospike wire protocol is a request-response protocol over a TCP connection. In order to write a record to a cluster, a client sends the cluster a write request that includes the record data to be written; in return, it receives a response from the cluster that tells it whether its write operation was successful. If the latency between the client’s request and the cluster’s response is very low, a pretty simple and robust scheme is sufficient to attain high throughput, as follows:
Send request #1
Wait for response #1
Send request #2
Wait for response #2
Etc.
Let’s examine why this is the case. Suppose that the client and the cluster are on the same LAN; the latency is thus 0.2 ms. This allows us to complete one request-response cycle every 0.2 ms, for a total of 1,000 ms / 0.2 ms = 5,000 request-response cycles per second – or 5,000 TPS. For higher throughput, we can run this simple scheme on multiple TCP connections in parallel. With two TCP connections driven by two threads or by one thread using non-blocking I/O, we obtain twice the throughput: 10,000 TPS. As throughput growth is linear in the number of TCP connections, all it takes us to support 100,000 TPS is 100,000 / 5,000 = 20 parallel TCP connections. This is how Aerospike clients have worked traditionally. Figure 1 below illustrates this scheme:
Now let’s look at the transatlantic scenario with a latency of 156 ms. Here, running the simple scheme on a single TCP connection yields 1,000 ms / 156 ms = 6.4 TPS. Wow! That’s pretty bad! Accordingly, in order to support 100,000 TPS, we would need 100,000 / 6.4 = 15,625 TCP connections. That’s a lot of connections! We wouldn’t be able to use individual threads for this, as spawning 15,625 threads is not practical. While non-blocking I/O could manage this number of TCP connections, opening thousands of TCP connections still seems wasteful: each TCP connection requires resources, e.g., memory buffers, on the machines on both ends of the connection. Moreover, splitting the same amount of data across fewer TCP connections means sending more data per TCP connection. This allows the TCP/IP stack to produce larger TCP segments, which means fewer TCP segments for – and, thus, fewer CPU cycles spent on – the same amount of data.
Thus the approach in Aerospike 3.8, which, as we shall see, is to switch to a less simplistic request-response scheme.
However, before we look into 3.8, let’s first validate the numbers that we have discussed so far. We run the C client benchmark on a machine in Boardman to write one-kilobyte records at a rate of roughly 100,000 TPS to a single-node Aerospike “cluster” in the same data center:
ubuntu@benchmark:~$ benchmarks -h 1.2.3.4 -n memory -k 100000000 -o S:1000 -w I,100 -z 55 -L 7,1
Experimentally, we found that it takes 55 threads to produce a write load of approximately 100 KTPS – the desired write load for this experiment – hence the -z 55 in the above command line. When run, the benchmark periodically outputs metrics like these:
2016-05-26 14:29:06 INFO write(tps=103253 timeouts=0 errors=0 total=3016232 pending=0) <=1ms >1ms >2ms >4ms >8ms >16ms >32ms write 100% 0% 0% 0% 0% 0% 0%
Note the write throughput of ~100 KTPS. As we can also see, the created scenario is fairly typical overall for an Aerospike deployment, i.e., we get sub-millisecond response times for client operations across a LAN link.
For the sake of illustration, we created a custom Aerospike server build that implements the simple request-response scheme outlined above across 10 parallel TCP connections. This modified build produces XDR metrics outputs such as these:
May 26 2016 14:29:06 GMT: INFO (xdr): (xdr.c:2010) throughput 62 : inflight 10 : dlog outstanding 720000 (delta 0.0/s)
While the client writes to the Aerospike server in Boardman, Oregon at ~100 KTPS, XDR replicates from Boardman to Frankfurt at a mere 62 TPS, which is pretty much in line with the 10 x 6.4 = 64 TPS expected for running our simple scheme across 10 parallel TCP connections.
Also note the inflight metric, which indicates the number of outstanding requests. For each of the 10 TCP connections, the Oregon Aerospike server spends most of its time waiting for a response from Frankfurt. That is why, for most of the time, there are 10 outstanding – or in-flight – requests: one on each of the 10 TCP connections. Hence, inflight 10.
A Better Way
Instead of throwing lots and lots of TCP connections at our problem, let’s now try to get the most out of a single TCP connection. Rather than writing records one by one, we could introduce batch writes. Imagine a world in which we write to Frankfurt in batches of 100. We bundle 100 write operations, send them off to Frankfurt via a single TCP connection, and receive 100 responses in return. This way, on this single TCP connection, instead of one write operation every 156 ms, we now manage to perform 100 write operations every 156 ms (i.e., 6.4 times per second), for a total of 100 x 6.4 = 6,400 TPS. The following figure illustrates this improved scheme:
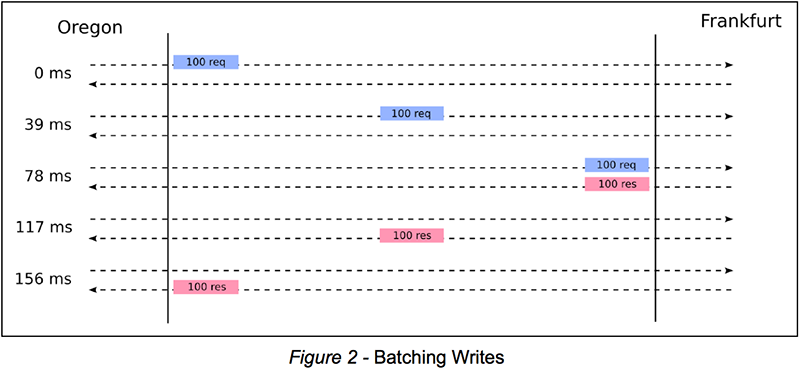
If we scaled this idea from batches of 100 to batches of 1,000, we would, instead, obtain 1,000 x 6.4 = 64,000 TPS on a single TCP connection. At first glance, it would seem that bigger batches are better. However, big batches lead to spikes: Frankfurt is idle for 156 ms, then receives a batch of 1,000 operations, processes these operations, sends back a batch response – and then becomes idle for another 156 ms, until the next batch. It would be nice if we could combine the advantage of our simple scheme (feeding writes to Frankfurt one by one to avoid spikes) with the advantage of batch processing (namely, higher throughput).
Both the simple scheme and the batch-based scheme complete one full request-response cycle on a TCP connection before issuing the next request. The difference is simply that the batch-based scheme handles more writes – one full batch of writes, to be exact – in each cycle, which makes it more efficient, but also “burstier”. Maybe it would be a good idea to ditch the strictly sequential execution of cycles altogether and, instead, interleave them.
So far, we have only considered the round-trip time of the link between Boardman and Frankfurt. Before we look at interleaving, it is necessary to add the bandwidth of the link to the picture. Suppose that the bandwidth is 1 MB (= 1,000 x 1,000 bytes, as opposed to 1 MiB = 1,024 x 1,024 bytes) per second. Further, suppose that we keep working with 1-KB (= 1,000- byte) records. Let’s assume that the size of the resulting write operations is also 1 KB. This neglects the overhead of TCP/IP and the Aerospike protocol, but it’s close enough, and easier to calculate with.
Suppose now that we send write operations W0, W1, W2, … via a single TCP connection to Frankfurt. Unlike what we did before, however, now we do not wait for a response to, say, W0 before sending W1. We simply keep sending.
156 ms – one round-trip time – after sending W0, Boardman receives Frankfurt’s response to W0. How many write operations has Boardman sent in the meantime, i.e., between sending W0 and receiving the corresponding response from Frankfurt? A bandwidth of 1 MB means that we can send 1,000 of our 1-KB write operations per second. Accordingly, it takes 1 millisecond to send a single write operation; in 156 ms, we thus manage to send 156 write operations. This is illustrated in Figure 3 below:
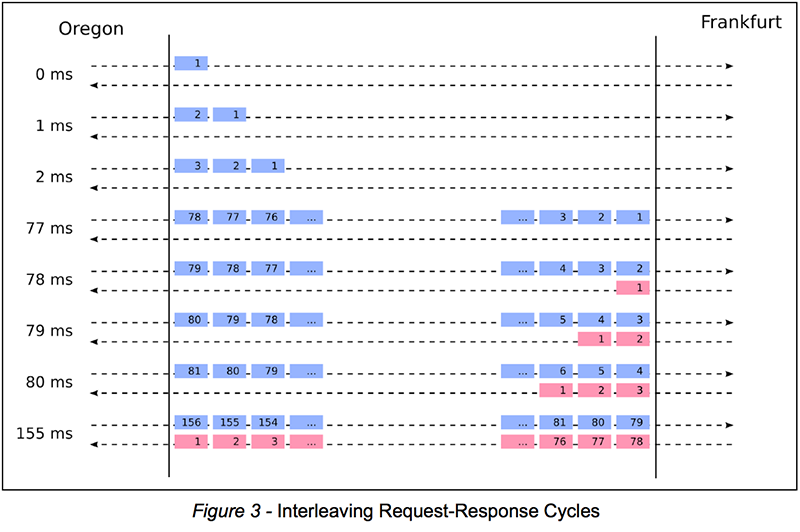
As we keep sending, we keep receiving responses for earlier writes. More specifically, when sending write operation Wn, we receive the response for Wn – 156. In other words, the responses lag 156 operations behind. Figure 4 below illustrates this observation:
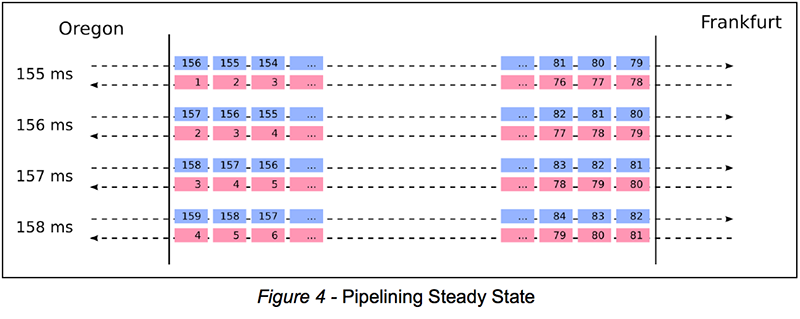
The idea of sending without waiting for responses, i.e., of interleaving subsequent request-response cycles, is referred to as pipelining. Indeed, support for pipelining is the biggest improvement to XDR in Aerospike 3.8.
With pipelining, what is the throughput that we can attain with a single TCP connection? This now depends solely on the available bandwidth. Pipelining completely eliminates the round-trip time from the throughput equation. The throughput is simply the available bandwidth divided by the size of a single operation: 1 MB/s / 1 KB = 1,000 TPS.
Let’s now increase our hypothetical bandwidth from the somewhat meager 1 MB/s to 100 MB/s, i.e., approximately 1 GB/s. We can now send 100,000 (instead of 1,000) of our 1-KB write operations per second. In other words, increasing the available bandwidth by a factor of 100 increases throughput by the same factor. Accordingly, in 156 ms, we now send 15,600 (instead of 156) write operations. Now the responses lag 15,600 (instead of 156) operations behind.
So what changes if our network link has the same 100 MB/s of bandwidth, but twice the round-trip time, i.e., 312 ms instead of 156 ms? We still get 100,000 write operations per second, as the throughput only depends on the available bandwidth. However, the responses now lag 31,200 (instead of 15,600) operations behind – twice as many as before. Again, we see that the round-trip time is now irrelevant for the attainable throughput. The only impact of the higher round-trip time is a proportionally longer response lag.
We validate this theory again by looking at the XDR metrics output of an unmodified build of Aerospike 3.8 under the same ~100k TPS of client write load we used in our experiment above:
May 26 2016 15:12:15 GMT: INFO (xdr): (xdr.c:2010) throughput 103798 : inflight 16817 : dlog outstanding 300 (delta -80.0/s)
At 103,798 TPS, XDR now keeps up with the client write load.
Reviewing the in-flight write operations of 16,817, we see that the number is pretty volatile; yet for the following calculation, we have to assume that it is constant over time. One round trip takes 156 ms, i.e., every 156 ms, all of the 16,817 in-flight write operations will have been completely handled and replaced by a fresh set of 16,817 in-flight write operations. As this happens every 156 ms, it happens 6.4 times every second. This means that we are performing 6.4 x 16,817 = 107,629 write operations per second – which roughly matches the 103,798 TPS indicated in the metrics output. This is close enough; keep in mind that we’re simplifying the calculation by assuming a constant number of in-flight write operations.
Overcoming TCP Limits
There is one additional thing that Aerospike 3.8 does in order to allow pipelining to realize its full potential: a little bit of TCP tuning. Let’s reconsider the example of a bandwidth of 100 MB/s and a round-trip time of 156 ms. As discussed above, we know that in this case, the response lag would be 15,600 operations. In other words, there would be 15,600 x 1,000 bytes = 15.6 MB worth of in-flight write operations at any point in time. This is important because of the TCP receive window.
The issues that TCP faces with high-latency links are the very same ones we address with pipelining – and its solution is pretty much the same as ours. In TCP, the equivalent to our requests is the data that is being transmitted by one end of the connection. The TCP equivalent to our responses is the acknowledgments (ACKs) sent by the other end of the connection for received data. If TCP were as simple as the simple scheme that we discussed at the beginning, it would send chunk #1 of the data to be transmitted, wait for the corresponding ACK #1 from the other end of the connection, send chunk #2, wait for ACK #2, etc. TCP would thus run into the same problems with high-latency links as our simple scheme.
Thus, just like us, TCP keeps sending data – without waiting for ACKs. However, it only does so up to a certain limit. Whereas we allow as many in-flight write operations as possible on a link with a given bandwidth and a given latency (e.g., 15,600 or 31,200 in the above examples), with TCP, the recipient can limit the amount of in-flight data. If we want 15,600 write operations in-flight to Frankfurt, we need to make sure that Frankfurt’s end of the TCP connection allows 15.6 MB of in-flight data. In other words, Frankfurt needs to announce a receive window of 15.6 MB.
When Aerospike 3.8 detects an incoming XDR connection, it automatically adjusts the connection’s receive buffer in such a way that the TCP stack announces a sufficiently large TCP receive window on the connection. Right now, the receive buffer size is always adjusted to 15 MiB.
The receive buffer size that a program can select is capped by the system-wide limit in /proc/sys/net/core/rmem_max. The Aerospike init scripts increase this limit to 15 MiB. In this way, the asd process can adjust its TCP receive buffers to this size for XDR connections. While we’re at it, we also increase the limit for TCP write buffers to 5 MiB. This ensures that there’s always data available when a TCP connection becomes ready to transmit more data.
These changes to the buffer limits in /proc are what makes the Aerospike init scripts output the following messages:
Increasing read socket buffer limit (/proc/sys/net/core/rmem_max): 212992 -> 15728640 Increasing write socket buffer limit (/proc/sys/net/core/wmem_max): 212992 -> 5242880
While all of this theoretically enables XDR to use a single TCP connection for replicating write operations via a high-latency link, we currently establish 64 TCP connections (plus one additional connection for client maintenance, for a total of 65 connections), as follows:
ubuntu@ip-1-2-3-4:~$ netstat -an | grep ESTABLISHED | grep 5.6.7.8 | wc -l 65
At the moment, pipelining does not support out of order responses. When Boardman, Oregon sends its write operations W0, W1, W2, etc. to Frankfurt, it expects to receive Frankfurt’s responses to the write operations in exactly the same order: response to W0, response to W1, response to W2, etc. In order to guarantee this order, Frankfurt processes all XDR write operations from a given TCP connection on the same CPU, strictly in sequence. Thus, at the moment, it takes multiple TCP connections to allow for parallelism in processing XDR write operations – 64 connections allow up to 64 CPU cores to be involved. Supporting out-of-order pipelining would allow the use of a single TCP connection. However, before we go down that path, we want to understand the real-world improvements for our users, with the changes described above.
Conclusion
XDR in Aerospike 3.8 is able to replicate a significantly higher write load across high-latency links than any of its earlier versions. It employs pipelining to completely take the round-trip time of the link out of the throughput equation. This enables XDR to keep up with client writes, even under extremely write-heavy workloads.
Obviously, this improvement in XDR has real-world implications, in particular for a few of our write-heavy users with data centers around the globe. In the real world (vs. this lab experiment), some of our users have reported an increase in XDR throughput of 10x or more after upgrading from Aerospike 3.7 to 3.8. As always, we are glad to get your input on the new version of XDR on our user forum, and to hear about your experience with this new technology.