For a system to operate at extremely high throughput with low latency, it should be able to not only scale out across nodes, but also scale up on one node, enabling:
- Higher throughput levels across fewer nodes,
- Better failure characteristics (the probability of node failure typically increases as the number of nodes in a cluster increase),
- An easier operational footprint (managing a 10-node cluster versus a 200-node cluster),
- Lower total cost of ownership (TCO), which is especially true once you factor in the SSD-based scaling described in the hybrid memory section.
This section details the system-level details behind Aerospike’s real-time engine that allow Aerospike to scale up to millions of transactions per second at sub-millisecond latencies per node.

Figure 1. Multi-Core Architecture
For data structures that need concurrent access such as indexes and global structures, there are three potential design models:
- Multi-threaded data structures with a complex nested locking model for synchronization, e.g., step lock in a B+tree
- Lockless data structures
- Partitioned, single-threaded data structures
Aerospike adopts the third approach in which all critical data structures are partitioned, each with a separate lock, reducing contention across partitions. Access to nested data structures like index trees does not involve acquiring multiple locks at each level; instead, each tree element has both a reference count and its own lock. This allows for safe and concurrent read, write, and delete access to the tree without holding multiple locks. These data structures are carefully designed to make sure that frequently and commonly accessed data has locality and falls within a single cache line in order to reduce cache misses and data stalls. For example, the index entry in Aerospike is exactly 64 bytes, the same size as a cache line.
How real-time engine works in Aerospike
In addition to basic key value store operations, Aerospike supports batch queries, scans, and secondary index queries. Scans are generally slow background jobs that walk through the entire data set. Batch and secondary index queries return a matched subset of the data and, therefore, have different levels of selectivity based on the particular use case. Balancing throughput and fairness with such a varied workload is a challenge, but it can be achieved by following three major principles:
- Partition jobs based on their type: Each job type is allocated its own thread pool and prioritized across pools. Jobs of a specific type are further prioritized within their own pool.
- Effort-based unit of work: The basic unit of work is the effort needed to process a single record, including lookup, I/O, and validation. Each job is composed of multiple units of work, which define its effort.
- Controlled load generation: The thread pool has a load generator that controls the rate of generation of work. The threads in the pool perform the actual work.
Aerospike uses cooperative scheduling whereby worker threads yield CPU for other workers to finish their job after x units of work. These workers have CPU core and partition affinity to avoid data contention when parallel workers access certain data.
In Aerospike, concurrent workloads of a certain basic job type are generally run on a first-come, first-served basis to ensure low latency for each request. The system also needs the ability to make progress in workloads that are long-running and sometimes guided by user settings and/or the application’s ability to consume the result set, such as scans and queries. For such cases, the system dynamically adapts and shifts to round-robin scheduling of tasks, in which many tasks that are run in parallel are paused and re-scheduled dynamically based on the progress they can make.
Rather than depend on the programming language or on a runtime system, Aerospike handles all its memory allocation natively. To this effect, Aerospike implements various special-purpose slab allocators to handle different object types within the server process. Aerospike’s in-memory computing solution effectively leverages system resources by keeping the index packed into RAM.
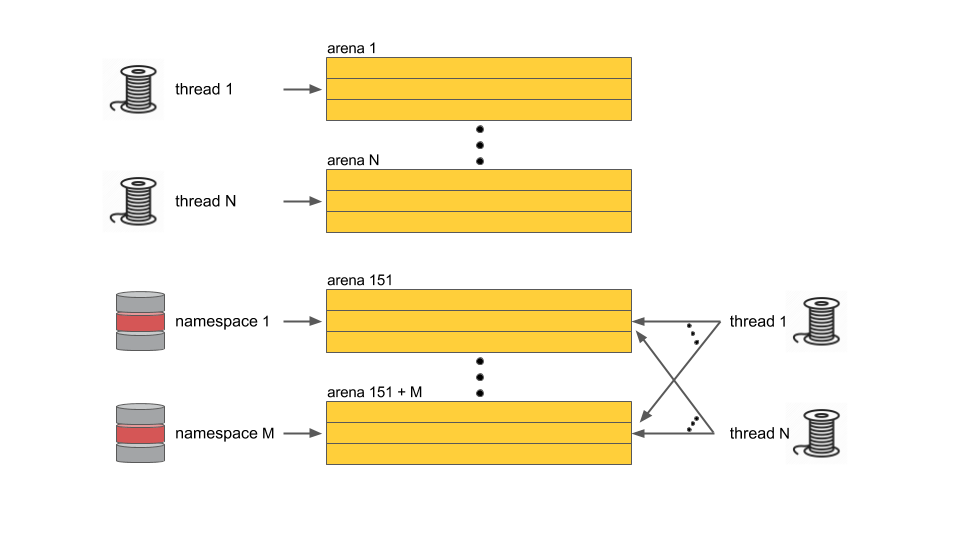
Specifically, as shown in the above figure, by grouping data objects by namespace into the same arena, the long-term object creation, access, modification, and deletion pattern is optimized, and fragmentation is minimized.